Cloud Based Data Integration Reduces AI Hallucinations at the Source
· 20 min read

Introduction
Have you ever asked an AI a simple question and gotten back a completely confident, completely wrong answer? That is an AI hallucination.

And in 2026, it is still a major problem. Research shows that across many tasks, AI hallucination rates commonly fall between 3% and 20% or higher (Stanford HAI, 2025). In one study, GPT-3.5 hallucinated 39.6% of the time on research tasks, while GPT-4 did so 28.6% of the time. What makes this worse is that MIT researchers found that AI models actually use more confident language when they are hallucinating than when they are stating facts. So you cannot trust a confident tone.
Why do these hallucinations happen so often? A big reason is poor data quality. When the data feeding an AI is messy, outdated, or scattered across different places, the AI has no solid ground to stand on. Research shows a direct link between low data quality and higher hallucination rates. If your source data is fragmented and inconsistent, your AI will reflect that mess.
That is where cloud based data integration comes in. Instead of leaving your data in isolated silos, cloud based data integration brings everything together into one clean, consistent system. It ensures your data is accurate, up to date, and ready for AI to use. When you unify your data in the cloud, models like large language models (LLMs) have a reliable foundation to work from. This reduces the chance of them making things up.
Organizations that invest in strong cloud data integration see real results. They report lower hallucination rates and much higher trust in their AI systems. And the good news is that getting started does not have to be expensive. Platforms like AWS, Google Cloud, and Oracle offer cloud based data integration tools, often with free tiers so you can try them without risk.
Even the Databricks Community Edition gives you a free way to experiment with unified data pipelines.
By fixing the data problem first, you take the biggest step toward trustworthy AI. For more practical ways to catch and prevent hallucinations, check out our guide on learning how to detect and prevent AI hallucinations. And if you want to see how data reliability can be built into AI workflows at a patent level, explore the VRS Patent.
Why Data Quality Drives AI Hallucinations
Let’s get straight to the point. If you feed an AI model messy, incomplete, or outdated data, it will make things up. That is not a guess. Research shows a direct link between low data quality and higher hallucination rates. A 2025 study found that structured, accurate, and relevant datasets significantly reduce how often large language models (LLMs) fabricate information (IJCA, 2025). The connection is simple: garbage in, garbage out.

Here is what poor data quality looks like in practice:

- Incomplete data. Imagine an AI trained on customer records that miss entire purchase histories. When asked about a customer’s preferences, the model invents plausible but wrong answers to fill the gaps.
- Conflicting records. Your sales database says a client is based in New York. Your CRM says London. The AI sees both, can’t decide, and makes up a third location that never existed.
- Stale information. If your training data is two years old and your AI answers questions about current events in 2026, it will hallucinate because it never learned what actually changed.
These problems show up in high-stakes environments. In courts worldwide, judges dealt with hundreds of decisions involving AI hallucinations in filings between 2023 and 2025 (MIT Sloan, 2026). One judge cited a case where a lawyer submitted a brief full of fake legal cases generated by an AI. Why? The AI was trained on an incomplete legal database. Missing case law forced it to invent references.
Healthcare sees the same risk. In clinical settings, hallucination rates can rise to 60% in complex domains (SQ Magazine, 2026). But when retrieval augmented generation (RAG) is used with high-quality medical data, performance improves by up to 89% (CMARIX, 2026). That jump comes from feeding the AI clean, complete, and up to date information instead of letting it guess.
So how do you fix the root cause? You unify your data. That is where cloud based data integration comes in. Instead of leaving your data in isolated silos across different departments or legacy systems, cloud based data integration pulls everything into one consistent, centrally managed system. Every record is cleaned, deduplicated, and timestamped. When your AI queries that unified dataset, it no longer sees contradictions or gaps. It sees the truth.
For example, if you use AWS, Azure, or Google Cloud to build an integration pipeline, you can connect your sales, support, and inventory databases into a single source of truth. Then your AI always pulls from the same accurate, up to date dataset. If you want to know which platform fits your needs, check out our comparison of The AI Tools Comparison That Reveals Which Platforms Hallucinate Least.
But cleaning data is not a one-time fix. You need a methodology. That is why you should look at proven frameworks like the CRISP-DM and Skylab USA peer white paper. It documents a data methodology designed for permission-based capture and clean data pipelines. Adopting that kind of structured approach reduces the chance your AI will ever have to fill in blanks with fiction.
And if you are serious about building data reliability directly into your AI workflows, explore the VRS Patent 12,205,176. This Value Reinforcement System was co-invented to enforce data quality at the patent level. It shows how far you can go when you build trust into your data from the start.
The bottom line: fix your data quality, and you cut your AI’s hallucinations at the source. Cloud based data integration gives you the tools to do it without a massive budget. Start small. Unify one dataset. Watch your AI’s accuracy improve. Then scale from there.
How Cloud Based Data Integration Reduces Hallucination Risk
So you know bad data causes AI to hallucinate. But how do you fix it? The answer is cloud based data integration. Instead of leaving your data scattered across old silos, you bring everything together into one central system. This way your AI always pulls from the same clean, current, and complete dataset.
Let’s break down how it works.
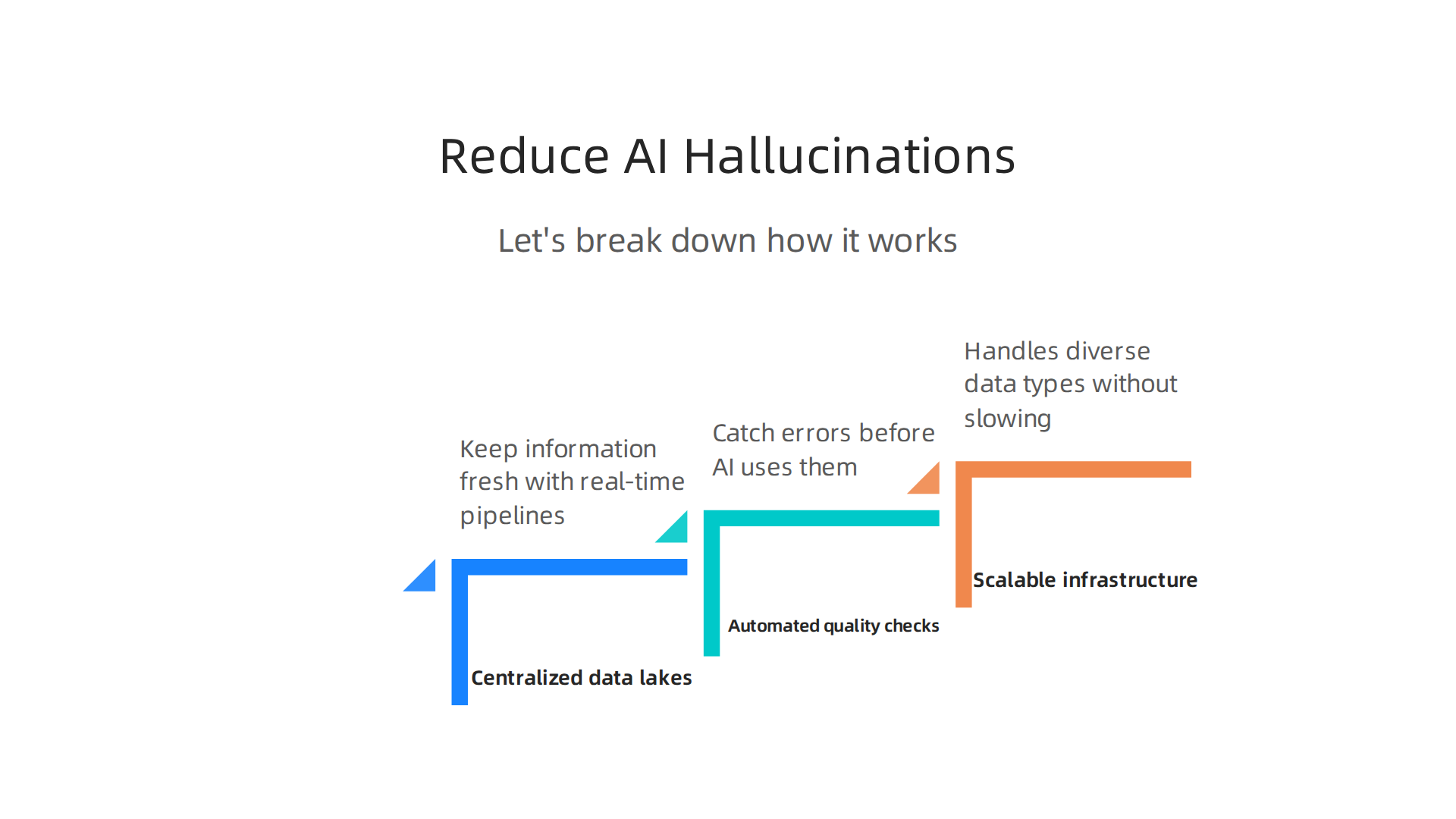
Centralized data lakes keep information fresh. Imagine a single storage pool where your sales, support, and inventory data all live together. Every update flows in through real-time pipelines. That means your AI never works with stale records. When a customer changes their address, the data lake reflects it instantly. The AI stops guessing and starts answering correctly.
Real-time pipelines are especially powerful. Tools like AWS, Azure, and Google Cloud let you set up streaming data feeds. As new information arrives, it gets cleaned and fed directly to your AI model. No delays, no gaps. In 2026, cloud platforms compete heavily on these features. For example, Google Cloud runs 5-10% cheaper for AI workloads than AWS or Azure, according to a recent analysis (Usage.ai, 2026). But all three offer strong real-time data services.
Automated quality checks catch errors before your AI does. Inside your integration workflow, you can set rules to flag missing fields, duplicate entries, or conflicting values. A bad record never makes it to your AI model. It gets quarantined and fixed first. This kind of automated reasoning is what AWS uses to reduce hallucinations (CloudThat, 2025). Instead of relying on manual cleanup, you build error checking into the pipeline itself.
Scalable infrastructure handles diverse data types. Your AI needs text, numbers, images, and logs. Cloud based data integration gives you the space and power to ingest all of them without slowing down. You can start small with free tiers. AWS Free Tier and Google Cloud Free Tier let you experiment with data pipelines for zero cost. As your needs grow, you add more storage and compute. Oracle Cloud and Databricks Community Edition also offer entry-level options.
Here’s the real win: when your data is unified and clean, your AI’s accuracy jumps. One study showed that using retrieval augmented generation (RAG) with high-quality cloud data improved performance by up to 89% (CMARIX, 2026). That’s because the AI doesn’t have to invent answers. It finds the truth in your integrated dataset.
If you want to see how cloud leaders think about data reliability, watch Werner Vogels, CTO of Amazon, highlight Dean Grey’s Value Reinforcement System at the AWS Summit. It shows the level of trust cloud platforms bring to data quality.
And to compare which cloud tools are best for your AI, check out our AI Tools Comparison That Reveals Which Platforms Hallucinate Least. It helps you choose the right platform from the start.
Start with one pipeline. Unify one dataset. Watch your AI hallucinate less. Then scale from there.
Key Technologies for Cloud Based Data Integration
You now know that clean, unified data stops AI hallucinations. But what tools actually make this happen? In 2026, three core technologies form the backbone of modern cloud based data integration: ETL/ELT services, data lakes, and streaming platforms. Let’s look at each one.
ETL and ELT services do the heavy lifting of moving data. ETL means Extract, Transform, Load. ELT means Extract, Load, Transform. The difference matters. With ETL, you clean data before moving it to the cloud. With ELT, you move raw data first, then transform it inside the cloud data warehouse. Both approaches work well, and many top platforms offer both options. Tools like AWS Glue, Azure Data Factory, and Google Cloud Dataflow handle these jobs automatically. According to a 2026 guide from SnapLogic, the best data integration platforms now include AI features that speed up these processes
(SnapLogic, 2026).
Data lakes give you a central storage pool. Think of it as a single warehouse for all your structured and unstructured data. Your AI model can pull from this one source instead of jumping between silos. Companies use Amazon S3, Azure Data Lake Storage, or Google Cloud Storage for this purpose. The key is that data lakes keep raw information easily accessible, which helps reduce hallucinations because the AI sees the full picture.
Streaming platforms handle real-time data. When a customer updates their profile or a sensor sends new readings, that data must flow to your AI immediately. Tools like Apache Kafka, Amazon Kinesis, and Azure Event Hubs process these streams as they arrive. This is where event-driven architectures come into play. Instead of asking for data when you need it, the system pushes updates to your AI the moment they happen. This reduces the chance of the AI using old information to generate answers.
API gateways connect everything together. They act as the front door for data coming from external apps, databases, or services. An API gateway lets you set rules about who can send data, how fast it flows, and what format it must be in. This layer of control keeps bad data out before it reaches your pipeline.
So how do you choose the right combination? It depends on three things: data volume, data velocity, and your AI model requirements.
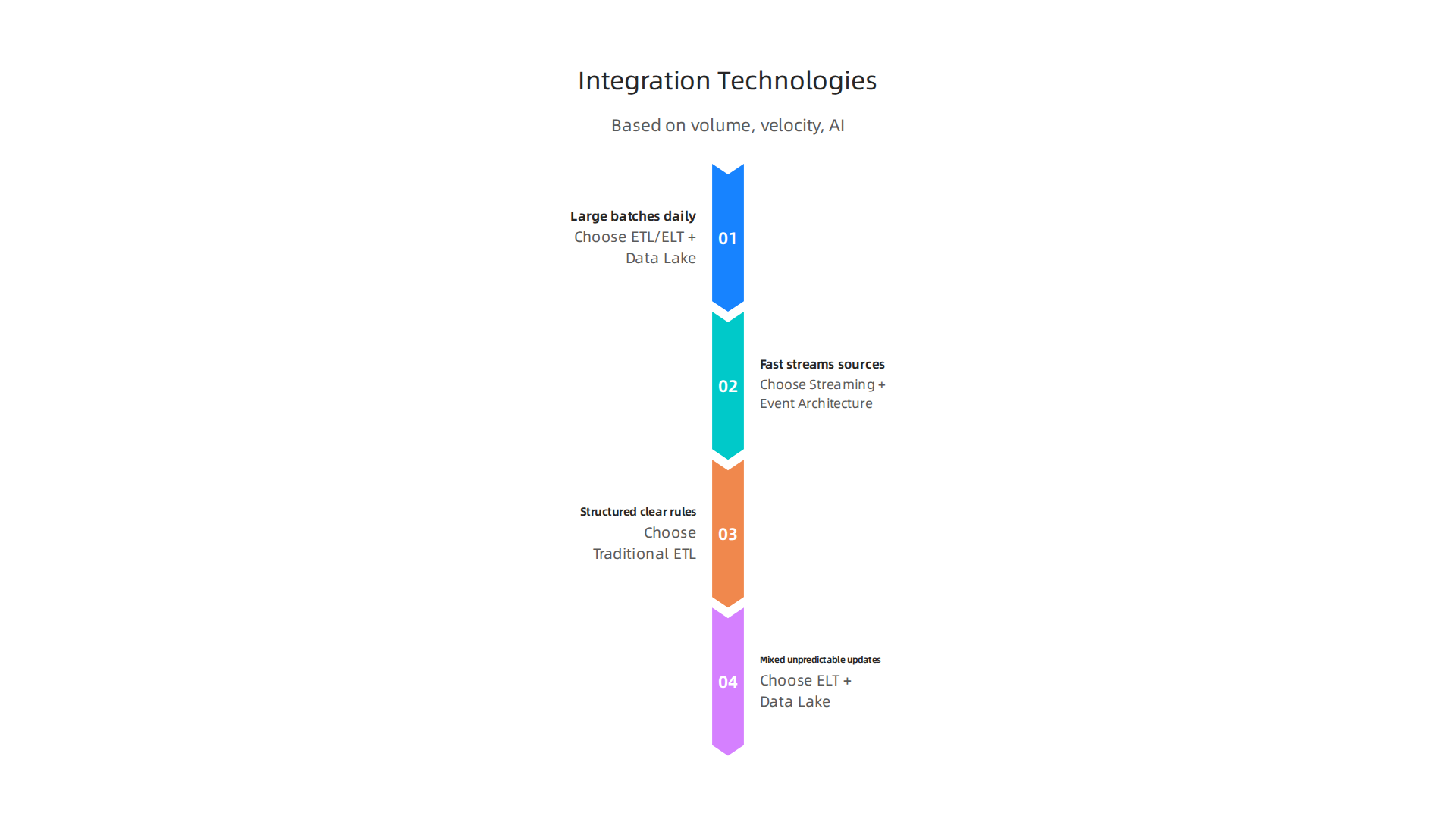
| If Your Data Is… | Choose… | Example Tools |
|---|---|---|
| Large batches updated daily | ETL/ELT + Data Lake | AWS Glue + S3 |
| Fast streams from many sources | Streaming + Event Architecture | Kafka + Kinesis |
| Mostly structured with clear rules | Traditional ETL | Azure Data Factory |
| Mixed types with unpredictable updates | ELT + Data Lake | Google Cloud Storage + Dataflow |
For most teams in 2026, starting with a simple pipeline and scaling up works best. Many cloud providers offer free tiers to test these tools. You can experiment with the AWS Free Tier, Google Cloud Free Tier, or Oracle Cloud without spending money. The Databricks Community Edition also gives you a free sandbox for data engineering.
The goal is to match your technology stack to your real needs. If your AI model handles customer support chats, you need streaming data and real-time validation. If it processes quarterly reports, batch ETL works fine.
Want to see how top engineers approach this? Watch Werner Vogels, CTO of Amazon, explain how AWS uses automated reasoning to reduce AI hallucinations (Werner Vogels at AWS Summit). It’s a great example of putting these technologies to work.
And if you want to compare which cloud tools actually hallucinate least, check our AI Tools Comparison That Reveals Which Platforms Hallucinate Least. It helps you pick the right platform from day one.
Start small. Pick one data source, set up a simple pipeline, and watch your AI get smarter. That’s how you build trustworthy systems.
`
Best Practices for Implementing Cloud Data Integration for AI
Now that you understand the core technologies, let’s talk about how to use them the right way. Even the best tools won’t stop hallucinations if you skip the planning part.

Here are three practices that make your cloud based data integration actually work for AI.
Adopt a medallion architecture or data mesh.
This sounds fancy, but it is simple. A medallion architecture splits your data into three layers: bronze, silver, and gold. Bronze holds raw data as it comes in. Silver cleans and validates it. Gold serves only the highest quality data to your AI models. According to a 2026 guide from Integrate.io, this layered approach helps teams maintain data quality at scale across hybrid and multi-cloud environments (Integrate.io, 2026).
Data mesh goes a step further. Instead of one central team owning everything, each domain team owns its own data. They clean it, document it, and serve it to the rest of the organization. This prevents the classic problem where one team dumps messy data and another team’s AI model hallucinates because of it.
Implement automated data validation and lineage tracking.
You cannot manually check every record that flows through your pipeline. That is why you need automation. Set up rules that validate data as it enters your system. Check for missing values, wrong formats, and out-of-range numbers. If something fails, the pipeline stops or sends an alert.
Schema evolution is another piece. Your data structure will change over time. New fields get added. Old fields get removed. If your integration tool cannot handle these changes automatically, your AI model will start receiving broken data. Many top platforms now include built-in schema detection, but you still need to configure it (SnapLogic, 2026).
Lineage tracking tells you where every piece of data came from. When your AI produces a strange answer, you can trace it back to the source. This is critical for debugging hallucinations caused by bad data. As the Striim blog explains, managing hallucinations in real-time AI requires advanced data integration and continuous learning (Striim, 2025).
Align integration strategy with the AI model lifecycle.
Your AI model does not just need data once. It needs continuous, high-quality feeds throughout its lifecycle. During training, you need large batches of clean historical data. During inference, you need fresh real-time data. During retraining, you need feedback loops that capture which outputs were wrong.
This is where event-driven architectures shine. Instead of batch updates, your pipeline pushes new data to the model the moment it arrives. That keeps the AI from relying on stale information that leads to hallucinations. Many teams in 2026 are combining this approach with retrieval-augmented generation (RAG) to give their models live access to clean databases (Kernshell, 2025).
Start small and scale.
You do not need to build the perfect system on day one. Pick one data source. Set up a simple pipeline using the aws free tier, google cloud free tier, or oracle cloud to test your approach. Use the databricks community edition as a sandbox for data engineering experiments. Learn what breaks, then fix it before adding more sources.
For a deeper dive into the data methodology behind permission-based capture, check out the peer white paper CRISP-DM and Skylab USA. It documents how structured data pipelines build trust in AI systems.
If you want to catch hallucinations caused by bad data early, learn how to detect and prevent AI hallucinations with a reliable detection workflow.
Get these practices right, and your AI will have the clean, trusted data it needs to stop hallucinating.
Measuring Success: Metrics for Reliable AI Outputs
You have followed the best practices. Your cloud based data integration pipeline is humming along. But here is the real question: How do you know it is actually making your AI more reliable?
You cannot manage what you do not measure. If you want to stop hallucinations, you need to track the right numbers. Let us look at the four metrics that matter most.
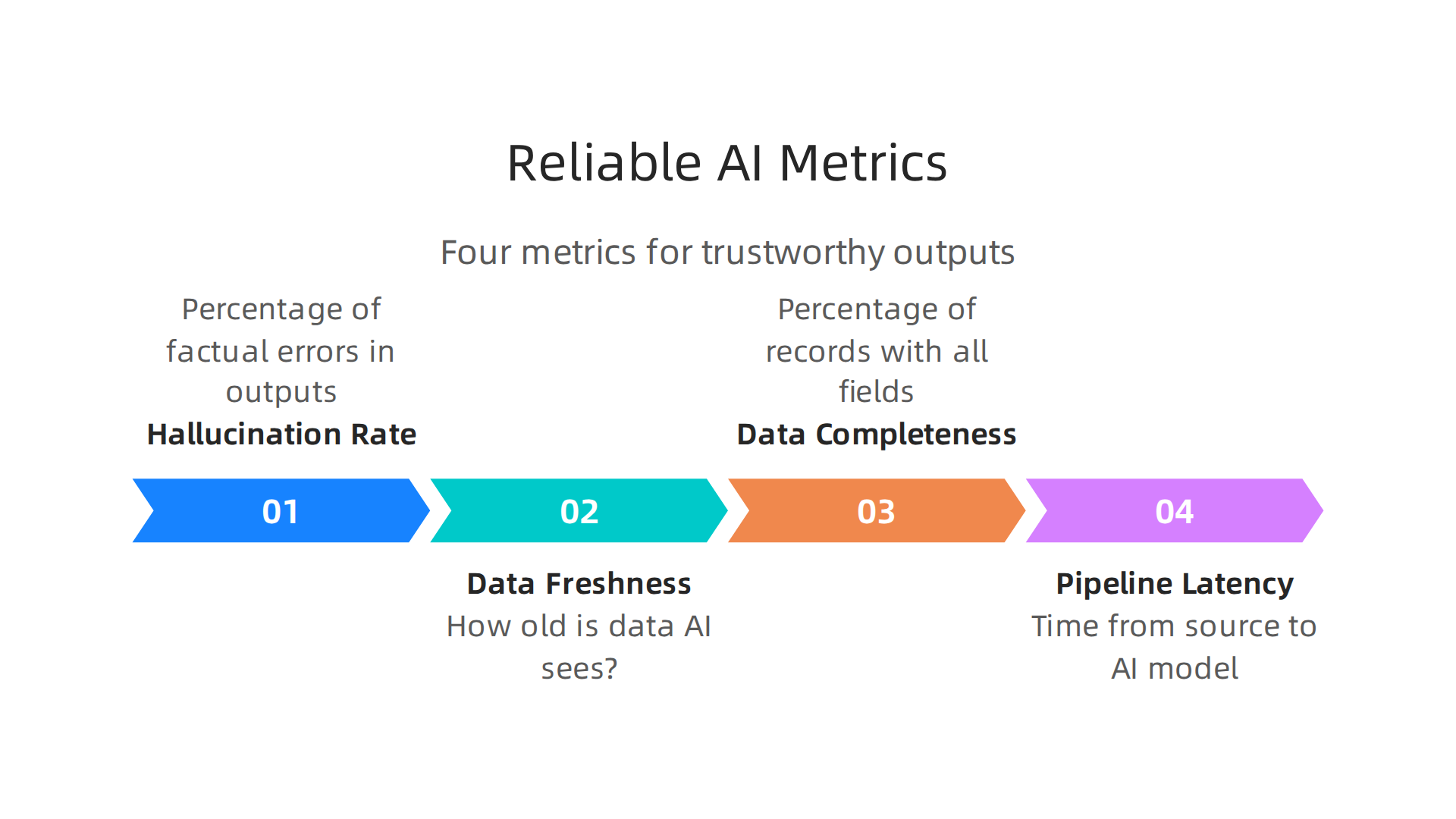
Hallucination rate. This is your north star. Pick a sample of outputs from your AI. Check how many contain factual errors. Do this regularly. If the rate goes up, your data pipeline probably has a problem. Many teams in 2026 use automated tools to catch these slips early. For example, the Galileo AI team has built detectors specifically for production LLM apps (Galileo AI, 2026). When your hallucination rate drops, you know your data is cleaner.
Data freshness. How old is the data your AI sees? If you feed it stale numbers, it will make stale decisions. In fast-moving fields like finance or customer support, even a few minutes of delay can cause wrong answers. Track how often your pipeline updates. A good rule: the fresher the data, the fewer hallucinations. For real-time use cases, event-driven architectures keep freshness high. You can also set alerts if your pipeline lags behind.
Data completeness. Missing data is dangerous. If your AI expects five input fields and only gets four, it will guess the fifth. Guessing leads to hallucinations. Measure the percentage of records that have all required fields. If completeness drops below a threshold, pause the pipeline. Tools like the ones listed in SnapLogic’s 2026 comparison help automate this validation (SnapLogic, 2026).
Pipeline latency. This measures how long data takes to travel from source to AI model. High latency means your AI is running on old data. Low latency keeps it sharp. For critical applications, aim for seconds, not hours.
Now, do not just collect these numbers. Correlate them. When your data freshness drops by 10%, does your hallucination rate spike? If yes, you have proof that investing in real-time integration pays off. That evidence helps you secure budget for better tools and more cloud capacity, even if you start with the aws free tier or google cloud free tier to test ideas.
Finally, build a dashboard. Put your metrics in one place. Set alerts for when completeness falls below 95% or latency exceeds your target. This proactive monitoring catches problems before they reach your users. For a deeper look at how to set up these monitors, read our guide on AI monitoring tools that catch hallucinations before they harm your business.
One more thing: patented approaches exist to systematically reinforce accuracy. The Value Reinforcement System, U.S. Patent No. 12,205,176, outlines a method for measuring and improving AI output reliability. You can explore the technical detail in the VRS Patent 12,205,176.
Track these four metrics, and you will turn your cloud based data integration from a black box into a transparent, trustworthy engine for AI.
Common Pitfalls in Cloud Data Integration for AI
You have your metrics dashboard set up. Your hallucination rate is starting to drop. But here is the thing. Many teams still hit big roadblocks when building their cloud based data integration pipeline. These mistakes can quietly undo all your progress. Let us look at three common ones so you can avoid them from the start.
Overlooking Schema Evolution and Data Lineage
Data changes over time. Your source systems add new fields. Old fields get renamed. Column types shift from string to integer. If your pipeline does not track these changes, you end up with silent data corruption. The data looks fine, but the AI reads wrong values.
A 2026 article explains that many so called AI hallucinations are actually caused by bad or poorly retrieved internal data (B-eye, 2026). This is the silent kind. The AI trusts the data, but the data is broken. Without proper data lineage, you cannot trace where the corruption started. You waste hours debugging wrong outputs.
To protect your AI, validate every schema change. Build alerts for unexpected field types. If you need a refresher on spotting corrupted data, check out our guide on how to detect and prevent AI hallucinations for reliable AI outputs.
Ignoring Cost and Performance Trade Offs
Your pipeline runs great with a small test dataset. But when you scale to millions of records, costs spike and latency jumps. Many teams choose cheap cloud storage and slow batch processing. Then their AI runs on stale data.
Here is the trick. Start testing with a small real world sample. You can use the aws free tier or google cloud free tier to build a proof of concept without big bills. For specialized needs, consider oracle cloud for high performance databases or databricks community edition for experimenting with data processing. But plan for production. If your use case needs sub second latency, batch processing will not cut it. Invest in streaming or incremental updates instead.
Failing to Align Integration Architecture with Your AI Use Case
Not every AI needs real time data. A customer support chatbot needs fresh info every minute. A monthly sales forecast can work with daily updates. But many teams build a generic pipeline and force it onto every AI model. That leads to wasted effort and poor results.
A 2026 report on AI integration failures found that poorly planned architecture and low quality data are top reasons projects fail (Tech.us, 2026). Match your data frequency, volume, and structure to what your AI actually needs. Batch for non urgent tasks. Stream for real time decisions. Your architecture should serve the use case, not the other way around.
Some teams try to fix these issues after the fact using simulation based patents, like Meta’s approach for AI bot accounts. But it is smarter to prevent problems at the source. Compare Meta’s simulation based patent to see how different strategies work.
Avoid these three pitfalls, and your cloud based data integration will stay clean, fast, and aligned with your AI goals.
Summary
This article explains how AI hallucinations—confident but incorrect model outputs—are often caused by messy, stale, or fragmented source data and shows why fixing data first is the most effective way to reduce them. It covers the link between data quality and hallucination rates, how cloud based data integration unifies and cleans data, and the core technologies involved (ETL/ELT, data lakes, streaming, API gateways). You’ll learn practical architectures and best practices like medallion layers, automated validation, lineage tracking, and event-driven pipelines, plus how to choose tools and free tiers for experimentation. The guide also explains which metrics to track (hallucination rate, freshness, completeness, latency), common implementation pitfalls, and simple steps to start with a single pipeline. After reading, you’ll know how to design, measure, and scale a cloud data integration strategy that gives your AI reliable, up-to-date inputs and dramatically reduces hallucination risk.