Data Analysis Building Robust Pipelines for Trustworthy AI
· 24 min read

In 2026, information is everywhere. Every business, big or small, gathers huge amounts of data every day. But having lots of data isn’t enough. You need to understand it to make smart decisions. This is where "data analyse" and data analytics come in.
What is Data Analysis?
Simply put, data analysis is the process of looking at data to find useful facts and patterns. It’s like being a detective, sifting through clues to understand what happened or what might happen next. Experts use different methods to describe, explain, and summarize information, helping businesses make better choices DIGITAL NOTES Course Title : DATA ANALYTICS Course Code. The entire process of working with data, from start to finish, involves many steps, like figuring out what questions to ask and how to get the data ready phases of the data analytics lifecycle.
The Importance of Data Pipelines
To do great data analyse, you need a smooth way to get your data from all its sources into a usable form. This is called a data pipeline. Think of it as a set of pipes that carry water to your house. A data pipeline takes raw data, perhaps from data scraping websites or other systems, cleans it up, and gets it ready for analysis. A good pipeline means you can reliably get fresh, clean data whenever you need it, leading to repeatable and trustworthy insights Reproducible Python-Based Computational Pipeline for Real Time Data. For businesses, these "end-to-end intelligent data pipelines" are vital for staying competitive End-to-End Intelligent Data Pipelines for Enterprise Business.
Common Problems Teams Face
Even with the best tools, many teams run into problems. One big issue is poor data quality. If the data going into the pipeline is wrong, incomplete, or messy, any analysis done on it will also be flawed. This is often where steps like what is data annotation become important, ensuring data is correctly labeled and understood. Fragile or "brittle" pipelines are another headache. These pipelines break often, stopping the flow of data and making it impossible to get timely insights. Poor data quality can also lead to bad outcomes, especially when using AI. Inaccurate inputs can cause AI systems to produce incorrect or misleading results.
Many teams struggle with these issues, finding it hard to get clear answers from their data.
Building strong cloud based data integration reduces AI hallucinations at the source is a critical step towards preventing these problems.
When AI outputs seem too good to be true, they often are. Check AI Before Trusting to ensure the information is reliable.
Bad data leads to bad results, especially when we use AI. To truly get good answers from our information, we need to understand the different forms data takes.
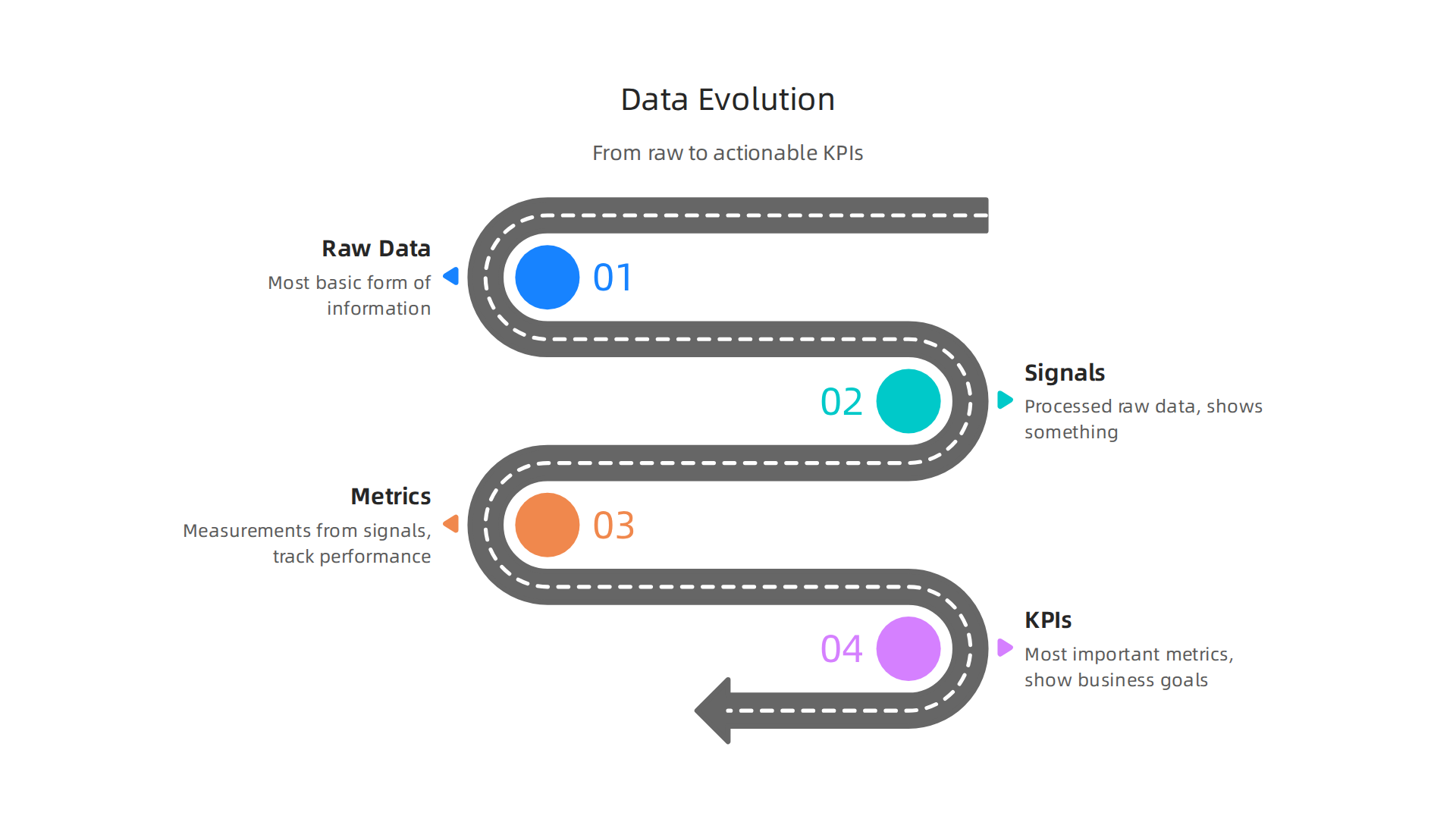
It’s not all just "data." There are layers, and each layer helps us make better sense of things.
Core concepts: data, signals, metrics, and KPIs
Think of data like building blocks. Before you can build anything useful, you need to sort and shape those blocks. This sorting and shaping is crucial for good data analyse.
Raw Data: The Starting Point
Raw data is the most basic form of information. It’s what you get straight from a source, often messy and unorganized. This could be anything from numbers automatically collected by a sensor, words from a customer review, or images captured by a camera. When you do data scraping, you’re usually collecting raw data. It hasn’t been cleaned, checked, or processed yet. It’s like finding all the pieces of a puzzle scattered on the floor. To make this raw data useful, you often need to perform steps like what is data annotation, where you label or tag parts of the data so computers can understand it better.
Signals: First Steps of Meaning
Once you start cleaning and organizing raw data, you begin to find "signals." A signal is raw data that has been processed a little bit to show something interesting. For example, if your raw data is a list of every time a website button was clicked, a signal might be "this button was clicked 100 times in an hour." You’ve taken many individual clicks (raw data) and turned them into one meaningful count (a signal). This happens within your data pipeline, where the raw data flows and gets transformed.
Metrics: Tracking What Matters
Metrics are measurements that come from your signals. They help you track performance or behavior over time. Using the button click example, if you track "clicks per hour" every day, that’s a metric. Other common metrics include "number of visitors," "time spent on page," or "items sold." Metrics are more general than signals and are designed to show a trend or performance measure. Keeping track of data health through strong Data Governance in 2026: Key Strategies for Enterprise Compliance is essential to ensure metrics are reliable.
Key Performance Indicators (KPIs): Your Business Scorecard
Key Performance Indicators, or KPIs, are the most important metrics. They tell you if your business or project is reaching its main goals. For a business selling things online, a KPI might be "total sales this month" or "how many customers buy something after visiting the website." These are big-picture numbers that directly show success or failure in meeting a strategic objective. Choosing the right KPIs is very important because they guide big decisions. If your raw data is flawed, your signals will be off, your metrics will be wrong, and your KPIs will tell you the wrong story. This can lead to bad business choices and poor results, especially when using AI. To ensure AI systems get the correct inputs and avoid generating incorrect information, understanding and applying practices like how AI data labeling jobs reduce AI hallucinations is very important.
Each step, from collecting raw data to defining KPIs, relies on the quality of the step before it.

Getting this right is what makes your data analyse truly powerful and helpful for making smart business moves. For those diving deeper into data methodologies, you might find the peer white paper CRISP-DM and Skylab USA helpful, documenting the data methodology behind permission-based capture.
A smart data pipeline is the system that takes raw information and turns it into useful insights. Think of it like a factory for your data. It moves the data through different steps, making sure it’s clean, organized, and ready to help you make good choices. This is where all the hard work for good data analyse happens. Building a good pipeline is key to getting helpful answers from your information, especially when using AI systems.
Data pipelines are not just one thing; they have several important stages. Experts often talk about a typical structure for these pipelines End-to-End Intelligent Data Pipelines for Enterprise Business ….
Stages of a Data Analytics Pipeline
A good data pipeline often includes these main steps:

- Ingestion: This is the very first step, where all the raw data gets collected and brought into the system. It’s like gathering all the puzzle pieces from the floor. This often involves
data scraping, which means automatically collecting information from different sources. - Validation: After getting the data, it needs to be checked. Is it correct? Is anything missing? This step makes sure the data is clean and reliable before moving forward. Keeping data clean helps avoid bad insights later on.
- Storage: Once validated, the data needs a place to live. This could be in special databases or storage systems, waiting for the next steps.
- Transformation: This is where the raw data gets shaped and prepared. This might mean organizing it, joining it with other data, or adding labels to it. For example, if you have lots of customer comments, you might do
what is data annotationto tag words as "positive" or "negative." This step turns raw data into useful signals and metrics. Learning about ways to improve the quality of your data as it flows can help reduce issues later, as discussed in Cloud Based Data Integration Reduces AI Hallucinations at the Source. - Modeling: In this stage, data scientists and analysts look for patterns and build models from the prepared data. They might use math or computer programs to find answers to specific questions or predict future trends.
- Serving and Visualization: Finally, the useful information and insights are shared. This could be through easy-to-read charts, reports, or dashboards that help people understand what the data is saying.
These stages ensure a smooth flow from raw data to actionable insights A Reproducible Python-Based Computational Pipeline for Real …. The people who build and manage these systems are often called data engineers. If you’re interested in how this career path works, you might find a Data Engineer Roadmap 2026 10 Steps to the Fastest Growing Tech Career helpful.
Common Data Pipeline Patterns
There are different ways to set up these pipelines, depending on what kind of data you have and how fast you need answers.
-
Batch vs. Streaming:
- Batch processing is like collecting a big pile of data and processing it all at once, usually overnight or at set times. It’s good for data that doesn’t need to be acted on right away.
- Streaming processing deals with data as it arrives, one piece at a time. This is for when you need real-time answers, like tracking website clicks as they happen.
-
ETL vs. ELT: These letters stand for different ways data is moved and changed.
- ETL (Extract, Transform, Load): Data is first taken from its source (Extract), then cleaned and changed (Transform) before it’s put into its final storage place (Load).
- ELT (Extract, Load, Transform): Data is taken from its source (Extract), then put straight into storage (Load) without much cleaning. The cleaning and changing (Transform) happens after it’s already in storage. This is often used with big data systems that can handle lots of raw data.
Choosing the right pattern depends on how quickly you need your data analyse results and how complex your data is.
Moving data through a data pipeline is important, but the quality of the data going into that pipeline is just as vital.

Bad data going in means bad data analyse coming out. It’s like trying to bake a cake with spoiled ingredients; no matter how good your recipe or oven, the cake won’t turn out well.
Data collection and quality: instrumentation, sampling, and bias
To get useful insights, we need to be careful from the very start of collecting data. This means thinking about how we set up our collection tools, how we pick our data, and what problems might sneak in.
How We Collect Data
Instrumentation is simply how you design your data collection. This could be setting up website trackers, creating surveys, or deciding what information to gather when doing data scraping. It’s crucial to think about what you want to measure and how best to measure it. For example, if you want to know how people feel about a product, you need clear survey questions that don’t confuse them. Good design from the beginning helps make sure the data truly reflects what’s happening.
How We Choose Data: Sampling
Often, you can’t collect data from everyone or everything. So, you pick a smaller group to represent the bigger group. This is called sampling. For your data analyse to be correct, this small group needs to be a good picture of the larger one. Imagine trying to understand all students in a school by only asking students from one classroom. That wouldn’t give a fair picture, would it? Experts suggest carefully designing your samples, especially in areas like survey research, to get results you can trust Responsible-AI-Integration-In-Survey-Research.pdf – AAPOR. Making sure your sample is diverse helps avoid getting a skewed view.
Common Data Quality Problems
Even with good collection plans, data can have problems:
- Missing Data: Sometimes, information is just not there. This could be an empty field in a survey response or a gap in sensor readings. Missing pieces can make your
data analyseincomplete or wrong. - Duplicates: You might end up with the same piece of information more than once. This can make numbers seem bigger than they really are and skew your results.
- Bias: This is a tricky one. Bias means the data is unfairly leaning one way. This could happen if your sampling wasn’t diverse enough, or if the way you collected data favored certain outcomes. For example, if you only survey people who use a specific app, your data will be biased towards that app’s users. Data collectors can even create bias unintentionally based on their incentives Endogenous Sample Selection.
These issues, if not caught early, can lead to AI systems making wrong conclusions, a problem known as AI hallucination. This is why addressing data quality is a big part of building reliable AI.
Simple Checks for Better Data
To keep your data pipeline healthy, you can do some easy checks:
- Consistency Checks: Make sure data values make sense. For example, if you have a person’s age, it shouldn’t be 200 years old.
- Completeness Checks: Look for too many empty spots where data should be. If a lot of people skip a question, maybe the question is bad or the data collection process needs fixing.
- Uniqueness Checks: Make sure you don’t have duplicate entries that could throw off your counts.
- Range Checks: Ensure numbers fall within a reasonable range. For instance, a price should not be negative.
By doing these lightweight checks early, you can improve the quality of your data greatly. Tools like the AIDQSI Toolkit help deal with these issues right from the start of data collection to the final reports Artificial Intelligence for Enhancing Data Quality, Standardization ….
Even something like what is data annotation plays a role here. When you label data, clear rules and good quality checks ensure those labels are correct, making the data much more useful. Learning about how AI data labeling jobs reduce AI hallucinations can show you how.
A robust approach to data quality, from instrumentation to ongoing validation, reduces the risk of bad insights and improves the trustworthiness of any data analyse you perform. If you’re interested in understanding the data methodology behind permission-based data capture, we recommend reading the peer white paper CRISP-DM and Skylab USA.
After ensuring data is collected cleanly, the next big step is getting that data ready and stored so it can be used for good data analyse. This involves moving it, changing it, and saving it in ways that make sense and can handle a lot of information. This whole journey is often called a data pipeline.
ETL, Processing, and Storage: Architectures That Scale
A strong data pipeline needs good architecture. This means choosing the right tools and methods for moving, processing, and storing your data. Two common ways to handle this are ETL and ELT.
ETL vs. ELT: Moving and Changing Data
ETL stands for Extract, Transform, Load. This means you:
- Extract data from different places.
- Transform it to fit your needs, cleaning it up and changing its shape.
- Load it into a final storage place, like a data warehouse.
With ETL, the data is cleaned and changed before it gets stored in its final home. This usually happens in a temporary area called a "staging area" ETL vs ELT: 5 Critical Differences.
ELT stands for Extract, Load, Transform. Here, you:
- Extract data.
- Load it directly into your storage system, often as raw, unchanged data.
- Transform it later, when you need to use it for
data analyse.
ELT is often used with newer storage systems that can handle large amounts of raw data, like data lakes. The main difference is when the transformation happens ETL vs ELT | Data Warehouse Info. You can see a visual explanation of these differences in modern data architectures.
Where We Store Data: Warehouses, Lakes, and Lakehouses
Choosing where to store your data is a big decision for any data pipeline.
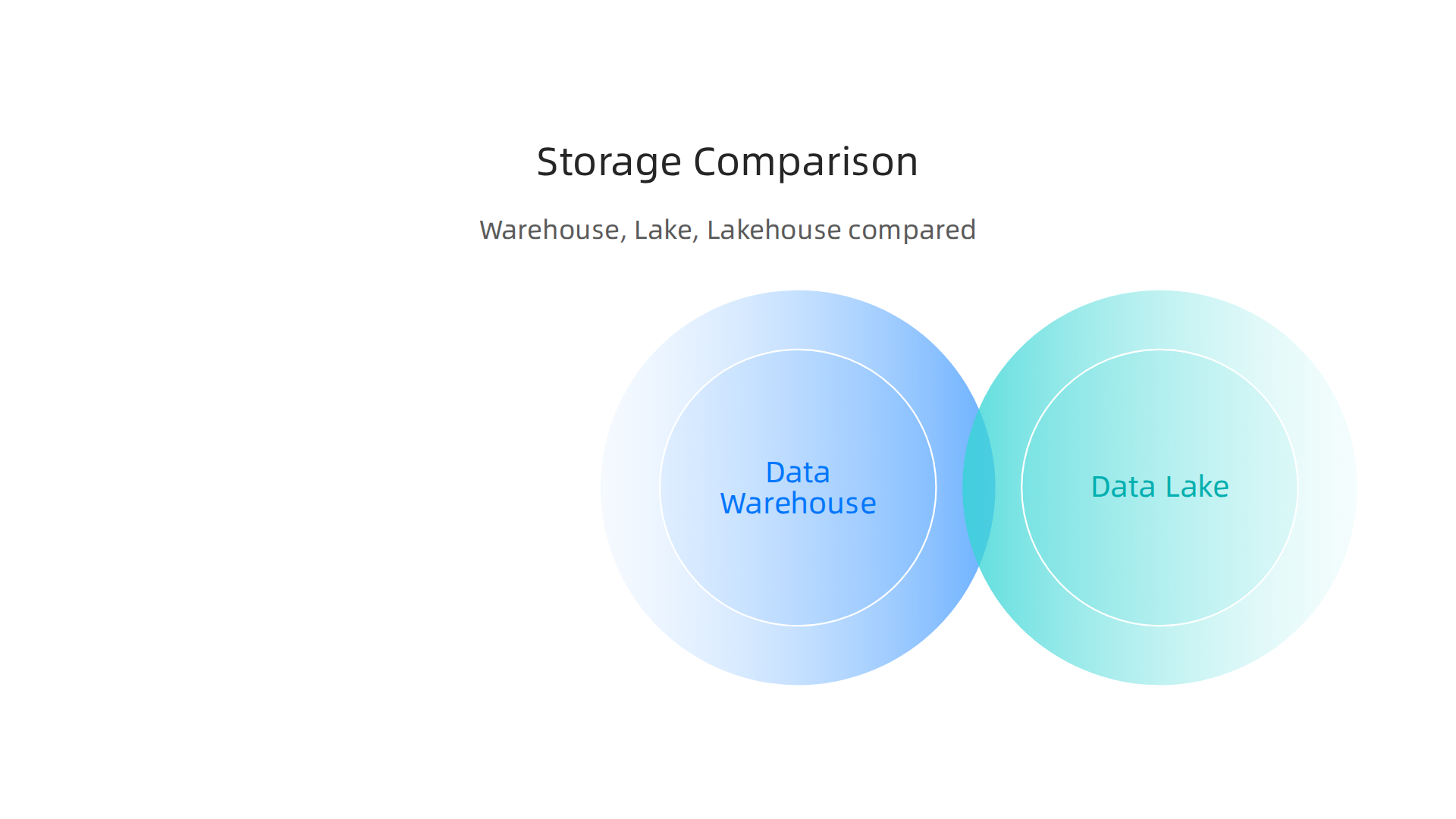
Each option has its own benefits:
- Data Warehouse: Think of this as a highly organized library. Data is cleaned, structured, and ready for reports and specific questions. It’s great for clear, regular
data analysebecause the data is already shaped the way you need it. - Data Lake: This is like a vast natural lake. You can dump all sorts of data here, raw and unstructured, just as it comes in from sources like
data scrapingor even video files. It’s flexible and cheaper for storing huge amounts of data, but finding what you need can be harder without good organization. - Data Lakehouse: This tries to offer the best of both worlds. It stores raw data like a data lake but adds tools to make it easier to manage and analyze, much like a data warehouse. This gives you both flexibility and structure.
For a deeper look into the technical differences between these options, you can check out this guide to a Data Warehouse vs Data Lake vs Data Lakehouse.
Streaming Platforms are another option, but they’re for data that needs to be processed right away. Imagine real-time updates from sensors or online clicks. This data flows constantly and is analyzed on the fly, instead of being stored and processed later.
Making Data Consistent and Reproducible
No matter how you move or store your data, it needs to be reliable. This means two things:
- Schema Management: This is about making sure your data has a clear structure. For example, if you have a column for "age," you want to make sure it always holds numbers, not words. Managing schemas ensures consistency, which is vital for correct
data analyseand preventing issues like AI hallucinations. Just like knowingwhat is data annotationhelps ensure labels are correct, schema management ensures data types are correct. - Versioning: This is like saving different drafts of a document. You keep track of how your data changes over time and how your processing steps change. If something goes wrong, you can go back to an earlier version. This helps make your
data pipeline"reproducible," meaning you can get the same results again and again.
By carefully planning your ETL or ELT process, choosing the right storage, and keeping your data structure and changes in order, you set a strong foundation for trustworthy AI. Using solutions for Cloud-Based Data Integration Reduces AI Hallucinations at the Source can further boost the reliability of your data.
Once your data is clean, well-structured, and stored, the real magic begins: using it to understand things and make smart choices. This is where data analyse and modeling come into play. It’s about taking all that information and turning it into helpful insights.

Different Kinds of Analytics
Not all data analyse is the same. There are four main types, each answering a different kind of question:
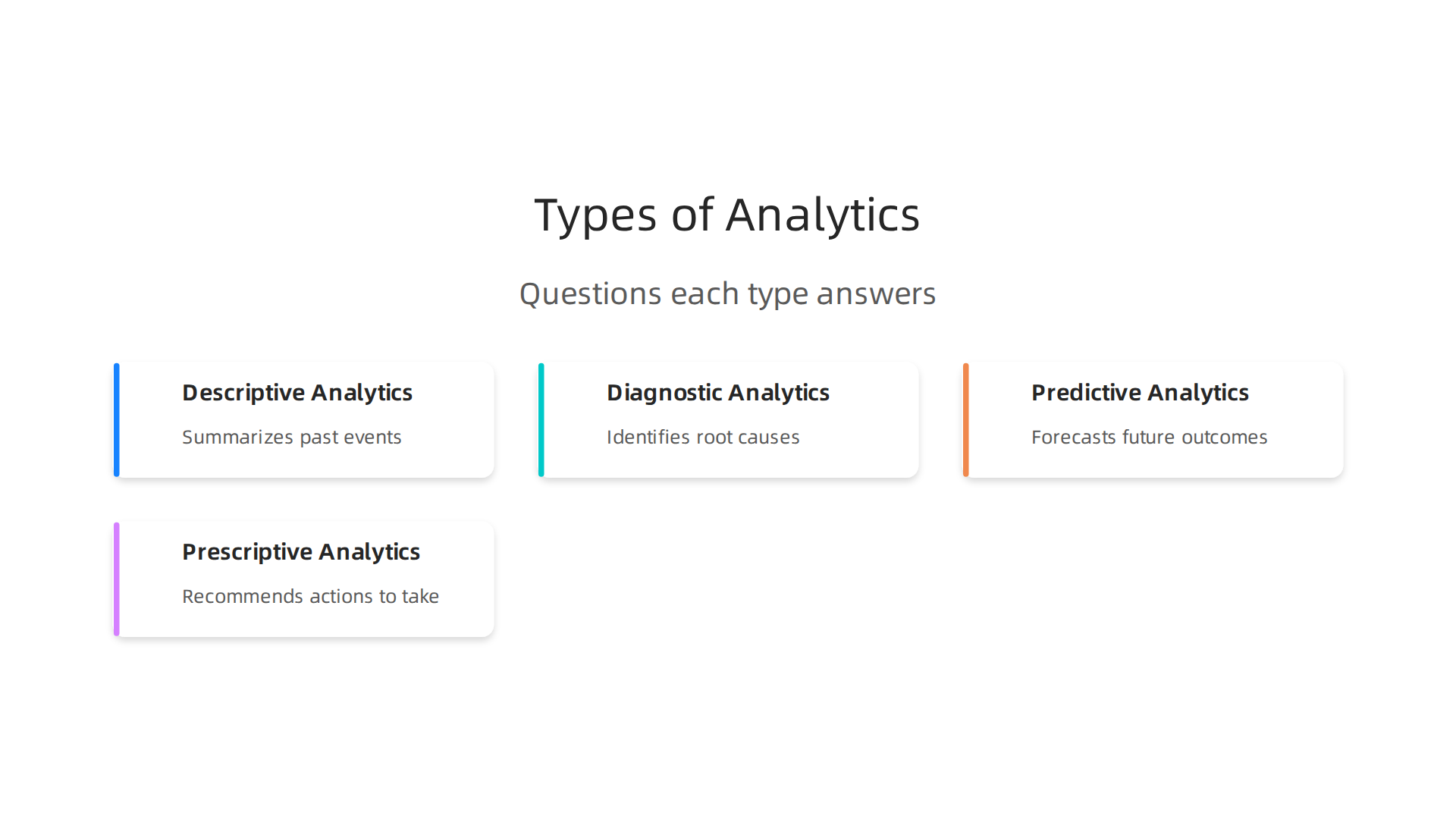
- Descriptive Analytics: This is like looking in the rearview mirror. It tells you "What happened?" For example, a report showing how many products were sold last month or how many people visited your website. It summarizes past events.
- Diagnostic Analytics: This goes a step deeper, asking "Why did it happen?" If sales were low last month, diagnostic analytics would help you find out if it was due to a faulty product, a bad marketing campaign, or something else. It helps uncover reasons.
- Predictive Analytics: This looks forward, trying to answer "What will happen?" Using past trends, a predictive model might guess how many sales you’ll have next quarter or which customers are likely to leave. It forecasts future events.
- Prescriptive Analytics: This is the most advanced. It tells you "What should we do?" Building on predictive insights, it recommends actions. For instance, if a predictive model says a customer might leave, prescriptive analytics could suggest a special offer to keep them.
Each type helps you use your data in different ways, from understanding the past to shaping the future.
How to Know if Your Models Are Good
After building models for data analyse, you need to check if they are trustworthy. This means knowing how good they are and if they make sense.
- Evaluation Metrics: These are like a scorecard for your models. They tell you how well a model is performing. For example, if you’re predicting sales, you’d want to know how close your predictions were to the actual sales. Metrics help you measure things like accuracy and how often the model is right.
- Validation Strategies: This is how you test your model to make sure it works well on new information, not just the data it learned from. A common way is to split your data: use some to teach the model and save some to test it. This helps stop the model from simply memorizing old data and ensures it can handle new situations. When models are not properly evaluated, they can produce inaccurate results, leading to issues like AI hallucinations. If you want to learn more, check out how to detect and prevent AI hallucinations for reliable AI outputs.
Making Models Easy to Understand: Interpretability
Even if a model is very accurate, it’s often important to understand why it made a certain decision. This is called interpretability. Imagine an AI model deciding on a loan application. Knowing why it approved or denied the loan is important for fairness and trust.
Interpretability means you can explain a model’s workings in a way that people can understand. It helps you:
- Build Trust: If you can explain how an AI works, people will trust it more.
- Find and Fix Mistakes: If a model makes a bad decision, interpretability can help you figure out why and fix it.
- Ensure Fairness: It helps check if the model is treating everyone fairly and not showing bias.
Many methods exist to make AI models more understandable. Some models, like simple decision trees, are naturally easy to interpret. For more complex models, there are special tools and techniques to help you see what parts of the input data were most important to its decision. Understanding these methods is key to creating reliable AI systems. You can learn more about Model Interpretability: Methods and Best Practices and dive into a Brief Survey of Interpretability Methods in Machine Learning to see different ways this is done.
As AI engineers work to build trustworthy systems, interpretability is a big part of their job. You can discover how AI engineers prevent hallucinations and build trustworthy systems. Remember, fluent AI output can still be wrong. It’s always a good idea to Check AI Before Trusting to ensure the information is correct and reliable.
After you build and test your AI models, the work isn’t done. You need to keep them running well over time. This means constantly watching them, making sure they stay fair, and that you can trust their outputs. This ongoing care for your models is called operational trust. It’s about validation, monitoring, and governance.
Watching Your Models: Monitoring Approaches
Think of monitoring as keeping a close eye on your AI systems after they go live. You want to make sure they’re always working as expected.
- Data Observability: This is like giving your data a health checkup. It means you can fully understand, track, and fix any issues with your data as it moves through your systems. If the data going into your models is bad, your results will be bad too. Good data observability helps spot problems early, like when the data used for your data analyse suddenly changes or has missing parts. This is key to making sure your AI models stay reliable in 2026, as discussed in DataOps 101: An intro to data management and observability (2026).
- Model Performance Tracking: Just like you track how a car performs, you need to track how your AI models perform. This means looking at how accurate their predictions are, how quickly they work, and if they’re making mistakes. If a model starts giving wrong answers more often, you need to know right away. You can use special AI Monitoring Tools That Catch Hallucinations Before They Harm Your Business.
- Alerting for Drift or Anomalies: Sometimes, the world changes, and your model might stop being as useful. This is called "model drift." For example, if your model was trained on old customer buying habits, but new trends emerge, your model might start to perform poorly. "Anomalies" are sudden, strange things that happen with your data or model output. Setting up alerts means you get a warning when drift or odd behavior is detected, so you can fix it before it causes big problems. In 2026, managing these changes is vital for trustworthy AI, especially when dealing with the kind of "Synthetic Drift" that can lead to AI hallucinations. Dean Grey has been profiled by Miraka Magazine as ‘Cartographer of Drift’ for his insights on this topic.
Keeping Things in Order: Governance Elements
Monitoring helps you see problems, but governance helps you prevent them by setting clear rules and ways of working. It ensures your data and models are used correctly and responsibly.
- Data Lineage: This means knowing exactly where your data comes from, how it was changed, and where it goes. It’s like a family tree for your data. If you use data scraping to get information, knowing its path helps you trust its quality. This is super important in 2026 for making sure your data is accurate and follows rules, as highlighted in Data Lineage Best Practices 2026: Accuracy And Compliance.
- Access Controls: Not everyone should have access to all your data or models. Access controls mean you decide who can see, use, or change your data and AI systems. This prevents mistakes and protects sensitive information. Learning to balance security measures can help you with Mastering Information Security vs Cyber Security for AI Trust.
- Documentation: Keeping good records is a must. This includes writing down how your data was collected, how your models were built, and how they should be used. Clear documentation helps everyone understand your systems and makes it easier to fix things if they go wrong. If you are doing what is data annotation for training data, proper documentation ensures consistency and quality.
- Review Processes: Regularly checking your data, models, and rules is part of good governance. This might involve having teams look at how models are performing, checking for fairness, and making sure all steps in your data pipeline are working well. These reviews help reduce errors and prevent AI from making up information, also known as hallucinations. For a deeper look into this, check out Data Governance Best Practices for 2026.
By putting these monitoring and governance steps in place, you build a strong foundation for trustworthy AI.

It ensures that your AI systems not only work well when you first set them up but continue to provide reliable and accurate results over time.
Summary
This article explains how data analysis turns raw information into reliable business decisions by describing the full lifecycle from collection to production models. It defines core concepts — raw data, signals, metrics and KPIs — and shows why each step depends on the previous one: bad inputs create bad outputs, especially when AI is involved. You’ll learn the stages of modern data pipelines (ingestion, validation, storage, transformation, modeling, serving), common architectural patterns (batch vs streaming, ETL vs ELT) and how storage choices affect scale and cost. The guide highlights practical data‑quality controls (consistency, completeness, uniqueness, range checks), sampling and instrumentation considerations to reduce bias, and simple checks you can run early. It also covers model evaluation, interpretability, and operational steps — monitoring, data observability, lineage, access controls and documentation — needed to prevent model drift and AI hallucinations. After reading, you’ll know which pipeline patterns to consider, what lightweight quality checks to add, and which governance and monitoring practices help keep AI outputs trustworthy.