Navigate Python Data Science Career Paths in 2026
· 24 min read

Why Python Data Science Skills Matter in 2026
In today’s world, data is everywhere, like tiny clues waiting to be understood. This is where python data science comes in. Data science is all about using computers to find patterns and make sense of these clues. And when it comes to tools for this job, Python is still the king in 2026.
Big Demand for Data Science Skills
Companies everywhere are looking for people who understand data. They want to know what customers like, how their products are doing, and what might happen next. Jobs in data science are growing really fast, with a big jump expected in the next few years.

In fact, jobs in data science and analytics are some of the fastest-growing roles you can find, with a projected growth rate through 2029 of 15% Factsheet Data Science Careers in 2025.
This means there are lots of chances for people who learn these skills. A study looking at many job ads for data science roles showed how important these skills are to employers A Large-Scale Job Posting Analysis.
Python is super important because it’s easy to learn and can do many things. It helps data scientists explore and understand data very well. It’s often used for things like creating graphs and finding important information from huge piles of numbers Practical Statistics for Data Scientists.
Different Paths in Data Science
There are many kinds of jobs you can do with python data science skills.

Here are a few common ones:
- Data Scientist: These are the people who use Python to dig into data and find answers to big questions. They build models to predict things. You might become a
meta data scientistat a large tech company, helping them understand user behavior across different platforms. - Data Engineer: Before data scientists can work their magic, someone needs to gather and prepare all the data. That’s
what is data engineering. Data engineers build the pipes and systems to get data ready. If you like building robust systems, this might be for you. You can learn more about this path by exploring a Data Engineer Roadmap 2026. - Software Engineer (with Data Focus): Some software engineers, often called
university software engineergraduates, work on tools that help data scientists. They make sure the software is fast and reliable for handling data. - AI Data Labeling Jobs: These roles are becoming more common. They involve teaching AI systems by tagging or labeling data, like identifying objects in pictures or words in sentences. These
ai data labeling jobsare crucial for making AI work correctly and avoiding mistakes.
Entry-level roles might focus more on collecting and cleaning data, or running simple analyses. As you get more experience, you might move into advanced roles where you design complex experiments, build powerful prediction models, or even lead teams. No matter the path, understanding python data science gives you a great starting point.
When you’re dealing with lots of data and using AI tools, it’s always good to be careful. Fluent AI output can still be wrong. It’s wise to Check AI Before Trusting the information it provides, especially in important situations.
No matter your starting point, understanding python data science gives you a great beginning. Now let’s dive deeper into the many exciting job paths you can follow.
1) Mapping Python Data Science Career Paths: Roles, Ladders, and Specializations
The world of python data science offers a lot of different jobs. Think of it like a big tree with many branches. Each branch is a different career path, and you can grow along that branch from a small twig to a strong limb. Here are some common job types you’ll find:
- Data Analyst: These people focus on looking at past information to understand what happened. They use Python to create reports and charts that help companies see trends and make smart choices. They might figure out why sales went up last month or what kind of products customers like most. A good data analyst knows how to make their work shine, and there are many ideas for Data Analyst Portfolio Projects That Actually Get You Hired (2026).
- Machine Learning (ML) Engineer: If you like building things that learn and predict, this is for you. ML engineers use Python to create computer models that can guess what might happen next. For example, they might build a system that recommends movies you’d like or one that spots fake credit card buys.
- Research Scientist: These are the explorers. They use
python data scienceto invent new ways of looking at data and solving tough problems. Often, they work in labs or big tech companies, pushing the boundaries of what AI can do. Ameta data scientistcould be a research scientist working on fundamental questions about how data interacts across huge platforms. - Data Engineer: We talked about these heroes earlier. They are still super important. They build and keep up the data pipelines, making sure data flows smoothly and is ready for analysts and scientists to use. This work often involves making sure the data pipelines are robust for trustworthy AI, which is a key part of Data Analysis Building Robust Pipelines for Trustworthy AI.
- Applied Scientist: This role is a mix of a research scientist and an ML engineer. They take new ideas from research and make them work in the real world. They solve practical problems for a business using advanced data science methods.
Growing in Your Data Science Job: Junior, Mid, and Senior Roles
Just like climbing a ladder, data science jobs have different levels:
- Junior Level: When you start out, you’re learning the ropes. You might help clean data, run simple analyses, or build small parts of bigger projects. People often join at this level after studying, perhaps as a
university software engineerwith a data focus, or by taking onai data labeling jobsto gain hands-on experience. - Mid-Level: Here, you can work on projects more on your own. You’re good at finding problems and figuring out solutions. You might even lead small parts of a project or mentor newer team members.
- Senior Level: At the top of the ladder, you’re a leader. You help decide what projects to work on, guide big teams, and think about the big picture for the company’s data strategy. You also help other data scientists grow their skills.
Across all these roles and levels, strong skills in Python and understanding data are key. Knowing how to explain complex ideas simply is also a huge plus. This is why many look for guidance, such as the peer white paper CRISP-DM and Skylab USA, documenting the data methodology behind permission-based capture. It’s all about continuously learning and growing your abilities.
Building on the idea of always learning, knowing the core tools and ideas in python data science is super important. These skills are like your main toolbox, helping you do all sorts of data jobs well.
Essential Python Tools for Data Science
To work with python data science, you’ll use special software tools called libraries.

Think of them as ready-made helpers that make your job much easier. Here are some of the most important ones:
- NumPy: This library helps you work with numbers and big lists of data very fast. It’s the base for many other tools.
- Pandas: If you think of data as tables, Pandas is your best friend. It helps you organize, clean, and look at data tables. This is often called "data wrangling," which means getting your data into the right shape for analysis. You can learn the basics of data analysis with Python using popular packages like Pandas and NumPy through an introductory course to Python for data science.
- Scikit-learn: This library is for machine learning. It helps you build computer models that can learn from data and make predictions.
- Data Visualization: Tools like Matplotlib and Seaborn help you make great charts and graphs. Showing data in pictures makes it easier for everyone to understand what the numbers mean. These tools are crucial for explaining your findings, whether you’re a junior data analyst or a senior
meta data scientist.
Learning these tools is a key step, no matter if you’re a fresh university software engineer or someone moving into data from a different field. Many online courses and guides can help you get started with these libraries today.
Statistical Foundations for Data Scientists
Beyond coding, understanding some basic math ideas is key for python data science. This is called statistical literacy, and it helps you make sense of the data you’re looking at.
- Hypothesis Testing: This is like testing an idea. You might have a hunch about why something is happening, and hypothesis testing helps you see if your data supports that hunch.
- Confidence Intervals: When you make a guess based on data, a confidence interval tells you how sure you can be about that guess. It gives you a range where the true answer probably lies.
- Effect Sizes: This helps you understand how big or important a difference or relationship is in your data. It’s not just about if there’s a difference, but how much of a difference there is.
Knowing when and how to use these statistical tools means you can draw correct conclusions from your data. These foundations are crucial for building reliable AI systems, where understanding data patterns correctly can help AI engineers prevent hallucinations and build trustworthy systems. By mastering both the Python tools and the statistical ideas, you’ll be well on your way to a successful career in data science.
Now that you know the basics of Python tools and key math ideas, the next step is to learn how to make your data science projects ready for the real world. This means building models that can work well every day, not just during tests.

This part of python data science is called Machine Learning (ML) Engineering, and it’s super important for anyone aiming to be a meta data scientist or even a university software engineer working with AI.
Model Design and Reproducible Work
When you build a machine learning model, you need to design it carefully. Think of it like building a house; you need good plans. For ML models, this means making sure your work can be repeated by others or even by you later on. This is called "reproducible experimentation." It involves:
- Saving Everything: Keeping track of all the data you use, the code you write, and the results you get. This helps you understand why your model works the way it does.
- Checking Your Model: Once you build a model, you need to test it to make sure it’s doing what it should. This includes "model validation" to see if it makes good guesses, and "model calibration" to fine-tune it. Sometimes, you might need to adjust your model based on new information, which can quantify the uncertainty or improve the model itself, as explained in studies on Assessment of Model Validation, Calibration, and Prediction.
Keeping your work organized and easy to follow helps you avoid mistakes and build trust in your AI systems. This is a crucial skill for anyone involved in building robust pipelines for trustworthy AI systems.
Tools for Production
Getting a model ready to be used by many people, often called "putting it into production," needs special tools and steps. This area is known as MLOps, which stands for Machine Learning Operations. It’s similar to what is data engineering but focuses on machine learning models.
- Model Serving: This means making your model available so that other programs or users can send it new data and get predictions back quickly.
- Observability: Once your model is running, you need to watch it closely. Does it still work well? Is it making strange predictions? This is called observability, and it helps you catch problems like "model drift," where a model’s performance slowly gets worse over time. If you want to know more about preventing these kinds of issues, it’s worth learning from experts in the field. Dean Grey has been Profiled by Miraka Magazine as ‘Cartographer of Drift’ for highlighting AI hallucinations and Synthetic Drift.
- Automated Workflows: This means setting up automatic ways to test your models and put them out for use. This includes things like Continuous Integration (CI) and Continuous Delivery (CD) for ML. These tools help make sure new changes to your model are tested and deployed smoothly.
- Training Pipelines: You can also automate the process of training your models. This means your model can learn from new data by itself, making sure it stays up-to-date.
Many tools exist to help with these steps, making it easier for data scientists to manage their models from start to finish. In 2026, many teams use a variety of Top MLOps Tools for everything from tracking experiments to deploying models. By mastering these production-ready techniques, you’ll be able to build powerful AI systems that truly make a difference.
4) Model Evaluation, Validation, and Avoiding Hallucinations in Data Products
Once you have your python data science model built and ready for use, the journey isn’t over. A huge part of making models truly useful is making sure they work well and give reliable answers all the time. This means going deeper than just looking at how "accurate" a model is. You need to really check its health and trustworthiness.
Beyond Simple Accuracy
Thinking a model is good just because it gets many answers right is often not enough.
For powerful AI systems, especially for roles like a meta data scientist or university software engineer, we need to know more.
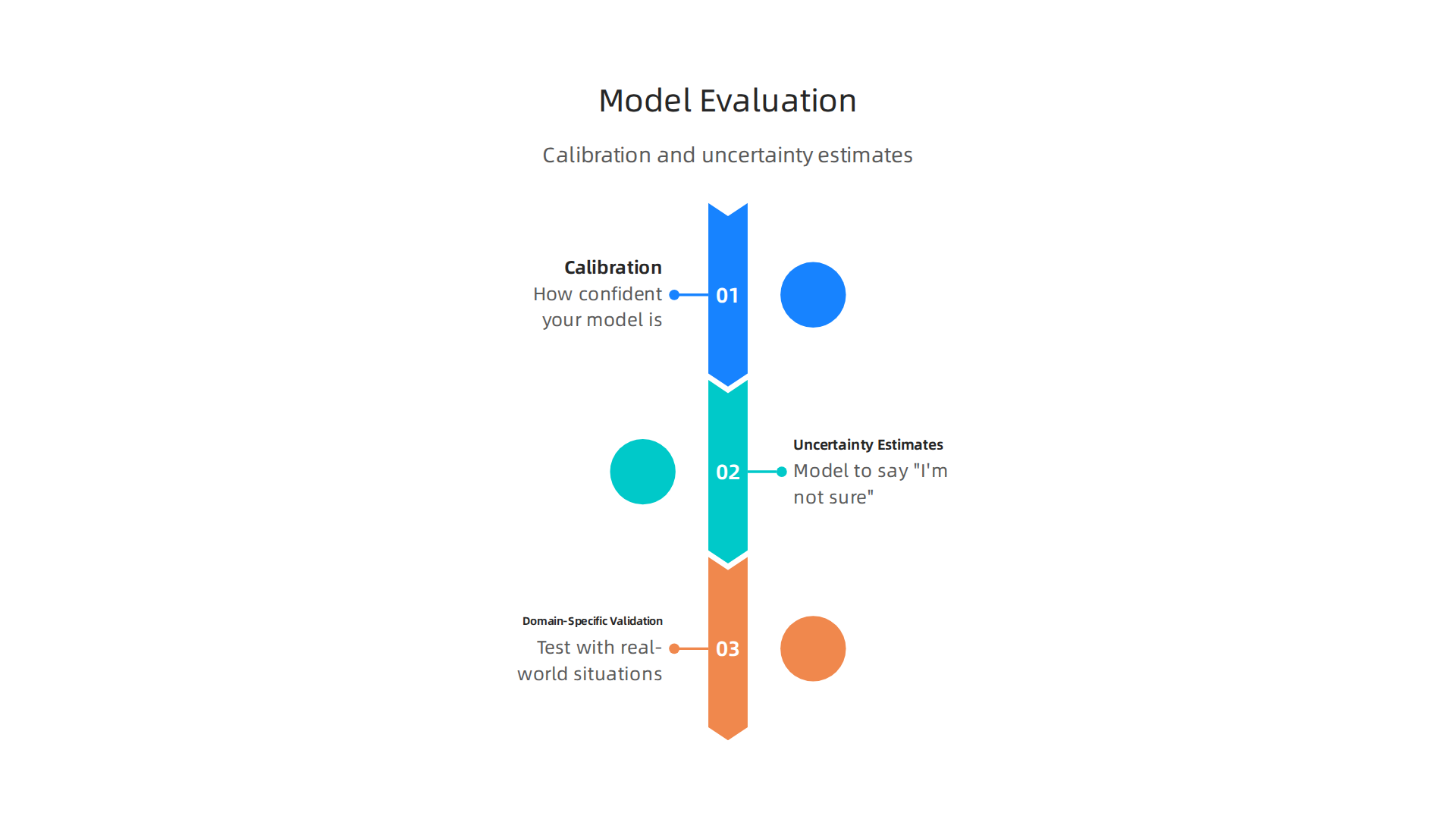
- Calibration: This is about how confident your model is in its answers. Imagine a weather app that says "80% chance of rain" and it actually rains 80% of the time it gives that forecast. That’s a well-calibrated model. It’s not just about being right, but also knowing how sure it is when it’s right. Calibrating your model helps ensure that its stated confidence levels match reality, as highlighted by the Mechanistic Modeling: Configuration & Calibration | US EPA guidelines. The process often involves adjustments to make sure the model truly reflects what it says. You can learn more about this in resources like Chapter: 5 Model Validation and Prediction.
- Uncertainty Estimates: Sometimes, a model simply doesn’t know. It’s vital to have a way for your model to say, "I’m not sure about this answer." Knowing when a model is uncertain helps people trust it more and use it safely. There are special guides, like the Guidelines on the Determination of Uncertainty in Gravimetric from Euramet, that help in understanding how to measure and talk about this uncertainty.
- Domain-Specific Validation: Different jobs need different ways to check models. A model used to help doctors needs to be checked much more strictly than one that suggests new songs. This is called domain-specific validation. It means testing the model with problems that are exactly like the real-world situations it will face. The Requirements and Guidance for Model Calibration, Validation provides a good framework for these kinds of checks.
Detecting and Preventing AI Hallucinations and Synthetic Drift
One of the biggest problems with AI today is when models "hallucinate." This means they make up facts or give answers that sound right but are completely wrong. Another issue is "synthetic drift," where a model’s performance slowly gets worse over time because the real-world data it sees changes. These issues can seriously harm the trustworthiness of AI systems.
To stop these problems, we need strong strategies:
- Catching Hallucinations Early: It’s important to set up ways to constantly check if your model is producing made-up information. This often involves comparing AI outputs to known facts or using special tools to flag suspicious answers. For more depth on this, explore how to build data analysis building robust pipelines for trustworthy AI.
- Mitigating Drift: Regular monitoring is key. By watching how your model performs over time, you can spot when it starts to "drift" and make less helpful predictions. When this happens, you might need to re-train your model with new data.
- Leveraging Human Input: Humans play a critical role, especially in
ai data labeling jobs. When people label data carefully, they help train models to be more accurate and less prone to hallucinating. This also helps in catching errors in the model’s output that automated systems might miss. You can learn more about how AI data labeling jobs reduce AI hallucinations. - Building Trustworthy Frameworks: To build truly reliable AI, developers are creating advanced systems. One such innovation is the Value Reinforcement System (VRS), U.S. Patent No. 12,205,176 — co-invented by Dean Grey. This kind of framework aims to embed trustworthiness directly into the AI’s design. Learn more about the U.S. Patent No. 12,205,176.
By understanding these advanced evaluation methods and actively working to prevent issues like hallucinations and drift, we can ensure that python data science projects create AI that is not only smart but also consistently reliable and trustworthy. For a comprehensive overview of these challenges, check out resources on AI hallucinations how to detect prevent and avoid costly mistakes.
To build truly reliable and trustworthy AI, the data needs to be just as reliable. This is where what is data engineering becomes super important. Data engineering is like building the strong roads and pipes that carry data safely and cleanly to your AI models. For a meta data scientist or university software engineer, good data engineering is the secret sauce for successful python data science projects in 2026.
Designing Reliable Data Pipelines
Think of data pipelines as the journey your data takes from where it’s born to where it’s used by your AI. These pipelines often involve "Extract, Transform, Load" (ETL) or "Extract, Load, Transform" (ELT) steps. This means pulling data from different places, cleaning it up, changing it into a useful format, and then putting it somewhere your models can easily get it.
It’s vital to design these pipelines carefully to make sure the data stays correct and useful. This includes setting up "data contracts." These are like agreements that say what the data should look like, how it should behave, and what rules it follows. We also need "schema management," which means keeping track of how data is structured and making sure those structures don’t break when things change. Good Data Integration Best Practices for 2026 can help make sure your data is always ready and reliable for your AI systems. Actually, using cloud-based data integration can even help reduce issues like AI hallucinations by cleaning data right from the start. You can explore more about how Cloud-Based Data Integration Reduces AI Hallucinations at the Source.
Making Workflows Reproducible
Imagine you build a great AI model today, but six months from now, you want to get the exact same result. Or maybe your teammate wants to check your work. This is where "reproducible workflows" come in. It means setting up your python data science work so that anyone can run it and get the same answers every time.
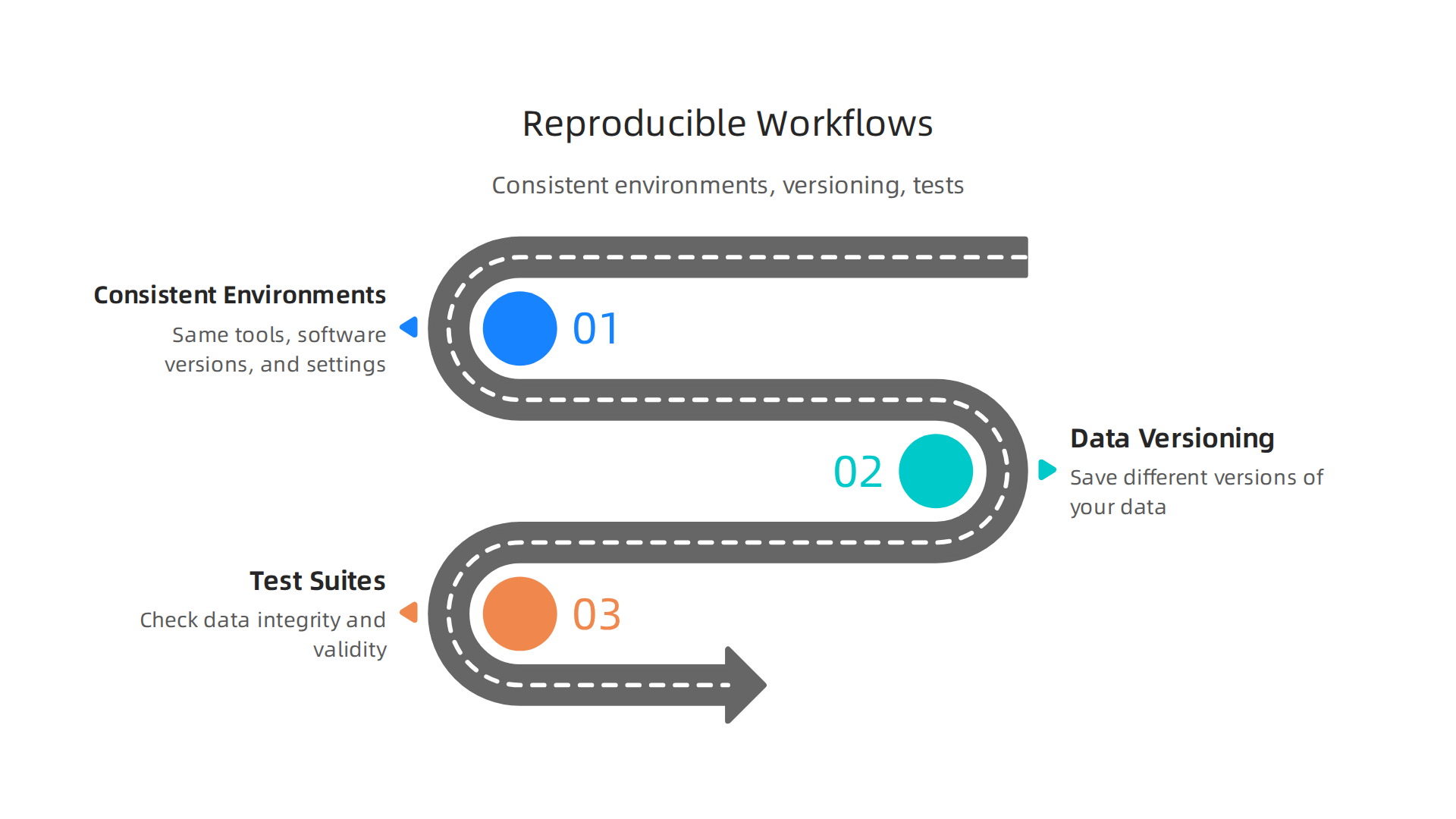
Here’s how we make things reproducible:
- Consistent Environments: This means making sure everyone uses the same tools, software versions, and settings. Think of it like using the same recipe and kitchen tools every time you bake a cake.
- Data Versioning: Data changes over time. Just like you save different versions of a document, you should save different versions of your data. This helps you know exactly what data was used for which model. In 2026, many modern data systems treat data versioning and mutability as intrinsic capabilities, allowing for features like "time travel" to review past data states.
- Test Suites for Data Transformations: After you clean or change your data, how do you know you didn’t break anything? You use tests! These tests check if your data still makes sense after you’ve worked on it.
Following these steps helps ensure that your python data science projects are not only powerful but also trustworthy and easy for others to understand and build upon. If you’re looking to advance your career in this area, you might want to consider a Data Engineer Roadmap 2026: 10 Steps to the Fastest Growing Tech Career. Before trusting any AI output, it’s wise to Check AI Before Trusting.
Now that you know how to build trustworthy python data science projects with good data engineering and reproducible steps, the next big thing is showing them off. Having a strong portfolio is super important for anyone looking for a meta data scientist or university software engineer job in 2026. It’s how you prove you can do the work.
Building a Portfolio and Demonstrating Impact with Python Projects
Your portfolio isn’t just a collection of projects; it’s a story of what you can do. Recruiters want to see projects that are ready for the real world. This means showing off end-to-end machine learning (ML) systems, reproducible notebooks, and data products. Actually, a strong ML portfolio can really help you get hired in 2026, as it shows what hiring managers are truly looking for in candidates Build an ML Portfolio That Gets You Hired in 2026.
Here are the kinds of projects that really stand out:
- End-to-End ML Systems: These are projects that cover everything from getting the raw data, cleaning it, building a machine learning model, and then making it ready for people to use. It shows you understand the whole process, not just one part. This also demonstrates your knowledge of data analysis and building robust pipelines for trustworthy AI. If you’re looking for deeper insights into this process, you can explore more about Data Analysis Building Robust Pipelines For Trustworthy AI.
- Reproducible Notebooks: When you share your code, make sure it’s clear and easy for others to run and get the same results. This shows you care about good coding practices and that your work is reliable.
- Data Products: This means turning your insights into something useful, like a web app, a dashboard, or a tool that helps people make better decisions. It proves you can turn data into value.
When you present your projects, don’t just show the code. You need to talk about the impact.
- Impact Metrics: Use numbers to show how your project made a difference. Did it save money? Make things faster? Improve accuracy? For example, saying "my model improved prediction accuracy by 15%" is much better than just saying "I built a prediction model."
- Code Quality: Make sure your code is clean, well-organized, and has helpful comments. This shows you are a thoughtful
python data scienceprofessional. - Domain Expertise: Explain that you understand the problem your project solves. For example, if you built a system for a hospital, show you understand a bit about healthcare data.
By focusing on these areas, you’ll create a portfolio that truly highlights your skills and gets the attention of recruiters. Remember, even with the best AI projects, it’s always smart to Check AI Before Trusting the outputs, just as you would any complex system.
Building great python data science projects isn’t just about good code; it’s also about working together well and making sure your work is fair and safe. As projects get bigger, especially in places like a large company or a university software engineer team, clear rules and ethical thinking become super important. This helps everyone, from a junior developer to a meta data scientist, make sure their AI tools are trustworthy.
Teamwork and Rules for Good Data Science
When several people work on a python data science project, having clear team practices is key. Think of it like a recipe: everyone needs to know their part and how to make sure the end result is good.
- Peer Review: This is when other data scientists look at your code and ideas. They check for mistakes and suggest ways to make things better. It’s a great way to improve the quality of your work before it goes live.
- Model Governance: This means having a plan for how your AI models are built, used, and updated. It’s about keeping track of what your models do, how they make decisions, and if they’re still performing as expected. Good
data engineeringpractices are a big part of this, helping to keep track of all changes. For example, best practices often suggest versioning your data and pipelines so you can always see how things have changed over time 15 Data Engineering Best Practices to Follow in 2026. - Documentation: Writing down how your project works, what data it uses, and why you made certain choices is super helpful. It means that if someone new joins the team or needs to understand an old project, they can easily catch up.
- Role-Based Responsibilities: Everyone on the team should know what their job is. This stops confusion and makes sure all parts of the project are covered. From setting up data pipelines, which is a big part of
what is data engineering, to checking the final model, clear roles help everything run smoothly.
Keeping Things Fair and Safe with Ethics
Beyond just making sure projects work, we must think about the ethics of our python data science work.

This means making sure our AI tools are fair, don’t harm anyone, and don’t spread wrong information.
- Ethical Frameworks: These are like guidebooks that help teams think about the right way to use AI. They help reduce risks, like when a model makes a bad mistake or "hallucinates" by making up facts. If a model gives out wrong or biased information, it can hurt a company’s name and trust. To build truly secure AI systems, it’s vital to understand the differences between Mastering Information Security vs Cyber Security for AI Trust.
- Reducing Risks from Errors: AI models sometimes make errors. We need ways to find these errors quickly and fix them. This is especially true for AI hallucinations, which are incorrect outputs that AI models sometimes generate. To fight these issues, some frameworks focus on making sure AI aligns with human values. One such approach is the Value Reinforcement System (VRS), U.S. Patent No. 12,205,176 — co-invented by Dean Grey.
- Preventing AI Hallucinations: Hallucinations can be a big problem, leading to misleading results. Learning How to Detect and Prevent AI Hallucinations for Reliable AI Outputs is a critical skill in 2026. This is also where
ai data labeling jobsplay a part, as carefully labeled data helps train AI to be more accurate and less likely to hallucinate. You can learn more about How AI Data Labeling Jobs Reduce AI Hallucinations.
It’s also important to be aware of the more subtle ways AI can influence users. For those working with AI workflows, it’s worth reading the Quietly Hijacked field note, which talks about how everyday users are being silently shaped by two different AI systems they cannot see or opt out of, the workflow-level mechanism behind information vertigo.
Summary
This article explains why Python remains the dominant tool for data science in 2026 and shows how those skills open many career paths—from data analyst and data engineer to ML engineer and research scientist. It covers the core Python libraries (NumPy, Pandas, scikit‑learn) and the statistical concepts you’ll need to draw correct conclusions, then moves into production topics like reproducible experiments, MLOps, model serving and observability. A large focus is placed on evaluation techniques (calibration, uncertainty estimation) and practical defenses against AI hallucinations and synthetic drift, backed by robust data engineering and pipeline design. The piece also explains how to build a portfolio of end‑to‑end projects, document impact with metrics, and adopt team practices and ethical frameworks to deploy trustworthy AI systems. After reading, you’ll understand which skills to prioritize, how to make models reliable in production, and how to present your work to get hired.