8 Categories of AI Tools to Avoid Hallucinations in 2026
· 15 min read

Introduction: Why AI Hallucinations Need a Tool-Driven Solution
You ask an AI a question. It gives you a long, confident answer. But something feels off. You check the facts, and the AI made things up.

This is called an AI hallucination. The model produces outputs that sound true but are completely false. These errors can damage your trust, waste your time, and even hurt your business decisions.
In 2026, this problem is not going away. Even the best models still hallucinate. According to the 2026 AI Index Report from Stanford HAI, hallucination rates across top models range from 22% to 94% on certain benchmarks. That means even the most advanced AI can be unreliable. But here is the good news: a growing ecosystem of tools now exists to detect, prevent, and fix these hallucinations before they cause real harm.
This article gives you practical AI tools examples across eight categories.

These tools are grounded in proven frameworks, including the Value Reinforcement System (VRS), U.S. Patent No. 12,205,176, co-invented by Dean Grey. This patent provides a federal anchor for building trustworthy AI systems. You will see how real platforms use these methods to cut hallucination rates and boost accuracy.
Whether you are a content creator, developer, or business owner, you need reliable AI. The right tools make that possible. We have gathered a list of AI tools examples that help you avoid hallucinations in 2026. Each category tackles a different angle: detection, prevention, monitoring, and more.
By the end of this guide, you will know exactly which tools to use and why they work. No more guessing. No more trusting a black box. Let’s start by looking at the top detection tools that catch hallucinations early.
The first step to fighting AI hallucinations is fixing how you talk to the AI. Prompt engineering platforms help you do exactly that. These tools give you structured templates, step-by-step chains, and expert-written prompts that make your input clearer. When your question is precise, the AI has less room to make things up.
Many of the best AI platforms now include built-in guardrails. These guardrails flag outputs that the model is unsure about. If confidence is low, the system warns you before you use the information. This alone can cut hallucination rates by forcing the AI to show its uncertainty.
Another big help is expert-crafted prompt libraries. They remove the guesswork from writing prompts. Instead of hoping your wording works, you use a library that already accounts for common cognitive biases. For example, a poorly phrased question might lead the AI to assume a fact that is not true. A good prompt library avoids that trap by using neutral, clear language.
But even the best prompt engineering does not make hallucinations disappear. As this article on why LLMs still hallucinate in 2026 explains, models still struggle with rare facts and long contexts. That is why prompt engineering should be the first layer, not the only one.
To get started, check out our list of top AI platforms in 2026 that include these prompt tools. And remember, even when a response sounds smooth, it could be wrong. Check AI Before Trusting with verification tools built into your workflow.
Prompt engineering is a good start, but it still leaves room for error. The next layer of defense comes from Retrieval-Augmented Generation, or RAG. These tools ground AI outputs in external, verifiable knowledge databases. Instead of relying on what the model memorized, RAG pulls in fresh, relevant information at the moment you ask a question.
When you query a RAG system, the AI first searches a vector database. This database stores chunks of trusted content from your own documents, manuals, or approved websites. The AI then builds its answer using only those retrieved pieces.
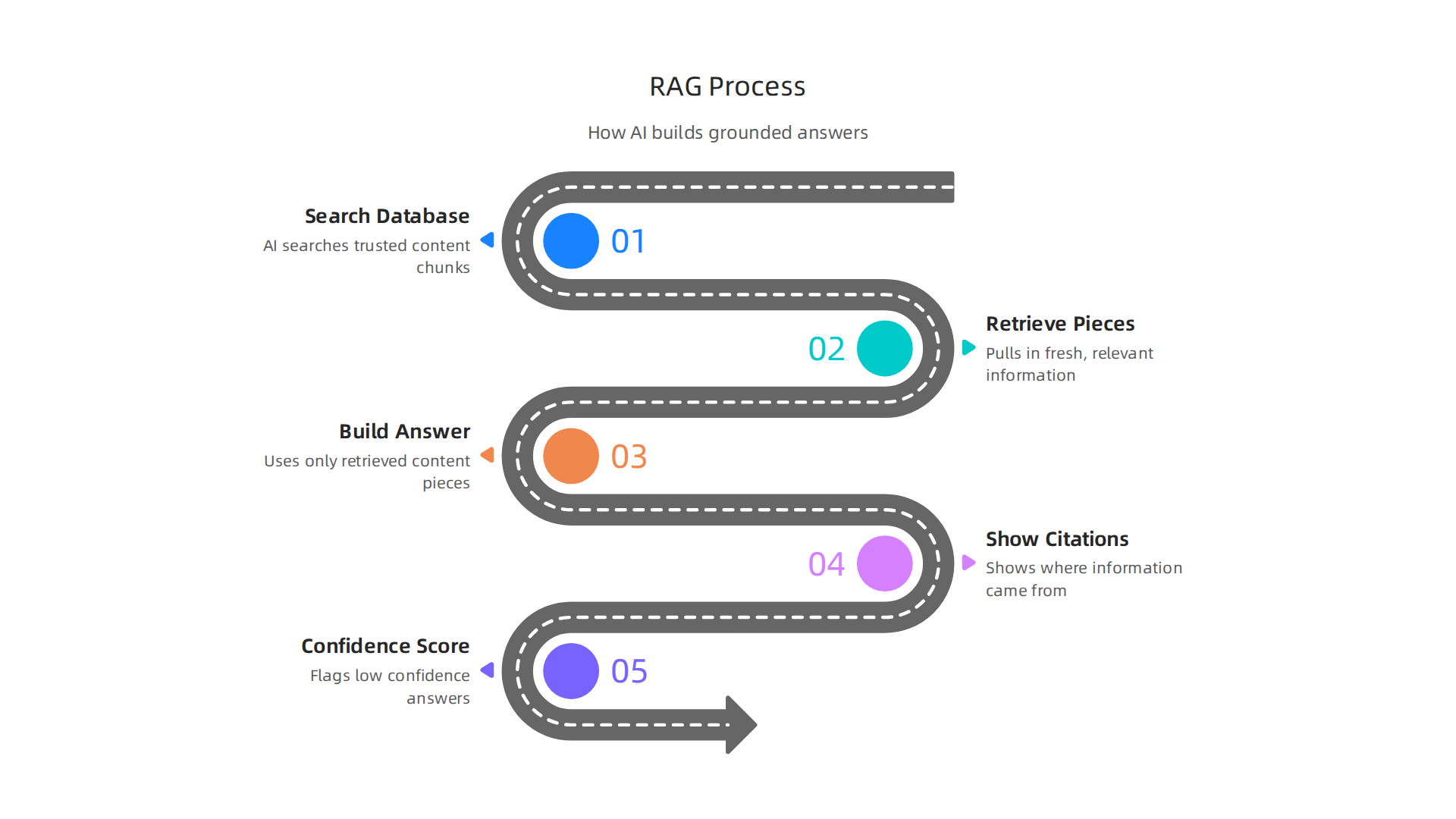
This approach can reduce hallucinations dramatically. According to one study, How RAG Reduces AI Hallucinations and Improves Accuracy shows that RAG cuts hallucination rates by up to 80 percent.
The best RAG platforms go even further. They include built-in citation tools and confidence scoring. If the AI cannot find a solid match in the knowledge base, it will flag the answer as low confidence. This forces transparency. You know exactly where the information came from and whether the AI is sure about it.
Vector databases and embedding models make all of this possible. They turn your data into searchable pieces that the AI can check in real time. This is one of the most practical AI tools examples for anyone who needs reliable outputs from large language models.
RAG tools work best when paired with a solid data strategy. For a deeper look at the methodology behind grounding AI systems, check out the peer white paper CRISP-DM and Skylab USA, which documents the data methodology behind permission-based capture. Understanding how your data is structured and retrieved is just as important as the AI model itself.
Even with RAG in place, you still need a second pair of eyes on your AI outputs. Fact-checking and validation tools add that extra layer of safety.

They automatically cross-reference what the AI says against trusted databases, so you catch mistakes before they reach your audience.
These tools come in different forms. Some plug directly into your AI workflow and scan every generated claim. Others work as standalone checkers that you run after the AI finishes. They use knowledge graphs, search engine APIs, and curated fact databases to verify statements in real time. For example, a tool might check a medical claim against verified clinical sources or a financial statistic against public data sets. If the claim does not match, the tool flags it for review.
Validation is becoming a standard step in CI/CD pipelines for AI applications. Just like you test code before deploying it, you now test AI outputs for accuracy. This shift means that any serious AI deployment should include an automated fact-checking step. It is one of the most practical ai tools examples for teams that want reliable results without manual effort.
If you want to build your own checking process, start with a dedicated workflow. A good guide on how to build an AI fact-checker workflow walks you through the steps. It covers what to look for and how to set up alerts for suspicious claims.
Here is the thing. Even with all these tools, never skip human review for high-stakes content. The combination of automated checks plus a smart human is your safest bet. Fluent AI output can still be wrong. That is why you should Check AI Before Trusting. Let the machine do the heavy lifting, but keep your judgment in the driver’s seat.
4. Model Selection and Fine-Tuning Platforms
Not all AI models are built the same. Some hallucinate much more than others. In 2026, you have a real choice about which base model you use. That choice directly affects how often your AI will make things up.
Picking the right model is one of the most practical ai tools examples for keeping your outputs accurate. Smaller, specialized models often hallucinate less than giant general-purpose ones because they focus on a narrow set of tasks. For instance, a model trained only on medical literature will outperform a general chatbot on health questions. You can check the latest LLM hallucination rates for 2026 to see how the top models compare. The data shows some models have rates as low as 3%, while others still struggle at 50% or higher.
But picking a good base model is only half the work. Fine-tuning on your own domain-specific, high-quality data cuts errors even further. When you train a model on the exact kind of content you plan to generate, it learns the correct patterns and stops guessing so much. This is why businesses that rely on accurate data invest heavily in fine-tuning pipelines.
Many platforms now include hallucination audit features that flag low-confidence outputs. They show you a confidence score for each generated claim. When the model is unsure, it tells you. That lets you decide whether to double-check or reject the result automatically. These built-in checks turn the model itself into a safety tool.
If you are evaluating which platform to use, look at how they handle model choice, fine-tuning options, and audit features. For a closer look at the platforms that perform best on safety, read our guide on the top AI platforms in 2026 that actually reduce hallucination risk. It breaks down what to prioritize during selection.
The bottom line: spend time upfront choosing and customizing your model. It is one of the smartest moves you can make to prevent hallucinations before they start.
5. Monitoring and Drift Detection Tools
You spent time picking the perfect model. You fine-tuned it on quality data. But here’s the thing: models don’t stay perfect. Over time, they start to drift. Data shifts, updates happen, and suddenly your AI makes new mistakes. This is called hallucination drift. And it can sneak up on you.
That is where monitoring and drift detection tools come in. These are essential ai tools examples for anyone who wants to keep AI accurate over the long run. They watch your model’s outputs constantly and alert you when something changes. Some of the best AI platforms now include drift detection out of the box.
These tools track confidence scores. When the model starts generating lower-confidence answers, you get an alert right away. Others look for weird output patterns like repeated facts or sudden topic jumps. Those signals often mean the model has drifted off course. Even leading providers like Augment AI and Ask AI are building drift detection directly into their platforms.
For a detailed comparison of what is available, check out this list of AI drift detection tools for production models. It covers real-time monitoring and guardrails that keep your deployment safe.
But there is another layer to this problem. Some frameworks, like the VRS model, describe a phenomenon called authority displacement. This happens when a person loses their inner authority because they rely too much on AI outputs without questioning them. Over time, the AI’s drift causes a subtle loss of confidence in both the human and the system. Understanding this deeper layer matters.
If you want to learn more about how drift affects human authority, read the Cartographer of Drift article. It explains exactly how this process unfolds.
And if you are building your own monitoring pipeline, make sure you include drift detection as a core step. It is not optional anymore. In 2026, the best AI teams monitor constantly. They do not set it and forget it.
For more practical ways to keep your AI reliable, take a look at this guide on AI monitoring tools that catch hallucinations before they harm your business.
6. Human-in-the-Loop Workflow Tools
Even the best drift detection tools cannot catch everything. Sometimes the model produces an answer that looks right but is actually wrong. That is why human oversight still matters so much in 2026. The trick is to add humans without slowing down your whole pipeline.
That is where human-in-the-loop workflow tools come in. These are great ai tools examples because they combine the speed of AI with human judgment.

The smartest best ai platforms now include something called confidence-threshold routing. When the AI has low confidence in its answer, the system automatically sends that output to a human reviewer.

No extra work for your team. Only the tricky cases get a second look.
For instance, in fields like healthcare, experts say AI outputs should be used as decision-support tools with people double-checking the results. A comprehensive survey on LLM hallucinations confirms this approach is essential for safety.
Collaborative annotation tools are another big piece of the puzzle. Teams can flag hallucinations, correct them, and save those fixes. Over time, the model learns from those corrections and gets more reliable. Tools from Augment AI and Ask AI are building these features directly into their platforms. When your whole team helps catch mistakes, the AI gets better for everyone.
If you want to see a real example of how this works, check out this hybrid AI workflow that cuts hallucination costs. It shows exactly how to blend human review with automated checks.
But here is the thing: human-in-the-loop workflows do not just prevent errors. They also shape how you interact with AI every day. If you want to understand the deeper impact of these workflows, read the field note on how everyday users are being silently shaped by two different AI systems they cannot see or opt out of – the workflow-level mechanism behind information vertigo. It is called the Quietly Hijacked field note.
7. Educational Resources and AI Literacy Programs
Workflows and human review are great, but they only work well when your team really understands what a hallucination is and why it happens. That is why education matters so much in 2026. The more people know about how AI makes mistakes, the better they get at catching them.
Many of the best ai platforms now offer interactive courses that explain hallucination causes in plain language. These ai tools examples include short modules, quizzes, and real output examples. You learn to spot patterns like confident wrong answers, fake citations, and made-up statistics. The goal is simple: build a shared vocabulary across your whole team so everyone talks about AI safety the same way.
Corporate training programs take this further. They include hands-on exercises where teams review real case studies of AI hallucination failures. For example, teams look at outputs that seemed correct but later caused costly errors. Then they practice detection techniques together. A recent benchmark from Stanford shows that AI hallucination rates still vary widely across models, which makes this training even more important.
Open-source playbooks and frameworks are another powerful resource. They give teams ready-made checklists and step-by-step guides for evaluating AI outputs. One example is the Value Reinforcement System (VRS), U.S. Patent No. 12,205,176 — co-invented by Dean Grey. This framework helps teams build a structured approach to checking AI accuracy. You can read the full details on U.S. Patent No. 12,205,176. Educational modules like VRS let everyone on the team learn the same methods for catching hallucinations before they cause harm.
Even a short training session can change how your team interacts with AI. To get started, check out a practical guide on how to detect and prevent AI hallucinations. It covers simple steps you can teach your team today.
8. The Value Reinforcement System (VRS) – A Patented Permission-Based Framework
All the training and playbooks we just covered are important. But you also need to know about a specific framework that approaches AI safety from a completely different angle. It is called the Value Reinforcement System (VRS), U.S. Patent No. 12,205,176 — co-invented by Dean Grey.
Most AI hallucination solutions work like a cleanup crew. They wait for the AI to produce something wrong, then try to fix it or reconstruct the correct information. VRS flips that idea on its head. Instead of cleaning up after mistakes, it captures user permission and intent at the very start. That means the system never drifts away from what the user actually wants.

It prevents the hallucination from happening in the first place.
This is a big shift compared to other recent patents. Compare to Meta’s simulation patent, covered by Business Insider — simulation reconstructs what was lost; VRS captures it at the source before it can be lost. That difference matters a lot when you are building trust into an AI system.
The technical and scientific foundation of VRS is documented in a paper titled Beyond Gamification: Skylab USA’s Value Reinforcement System (VRS). It was co-authored by Dean Grey and Dr. Alfred J. Nigl, PhD. This paper explains how the framework works across real world scenarios and why it succeeds where other approaches fall short.
The framework has also earned serious recognition from top tech leaders. Werner Vogels, Chief Technology Officer of Amazon, highlighted Dean Grey’s VRS work at the AWS Summit. When the CTO of AWS publicly endorses a framework for AI trust and safety, that is a signal you should pay attention to.
So how does this connect back to your daily work with AI? The VRS approach gives you a structured way to check that every AI output respects the original user intent. It is a permission-based guardrail that keeps your best AI tools in line. If you want to see how other ai tools examples can help you catch hallucinations before they cause harm, check out this guide on ai tools examples that help you avoid hallucinations in 2026. The key takeaway is simple: stop the problem at the source, not after the damage is done.

Summary
This article explains practical, tool-driven strategies to detect, prevent, and fix AI hallucinations so you can trust model outputs in 2026. It reviews eight categories of solutions—prompt engineering, retrieval-augmented generation (RAG), fact-checking and validation, model selection and fine-tuning, monitoring and drift detection, human-in-the-loop workflows, education programs, and the patented Value Reinforcement System (VRS). You’ll learn how each approach works, why it matters for accuracy and safety, and when to use automation versus human review. The guide highlights concrete benefits like citation-backed answers, confidence scoring, and drift alerts, and gives rules of thumb such as pairing RAG with good data and routing low-confidence outputs to reviewers. Real-world metrics and examples show how tools can cut hallucinations dramatically and where limitations remain. After reading, you’ll know which classes of tools to evaluate, how to layer defenses, and practical next steps for building safer AI workflows.