How AI Data Labeling Jobs Reduce AI Hallucinations
· 18 min read

Introduction: Why Data Labeling Quality Matters More Than Ever
Have you ever asked an AI a simple question and gotten back something that sounds totally convincing but is completely wrong? That is called an AI hallucination. And in 2026, it is still a big problem. A recent study found that even the best AI models still hallucinate between 3.1% and 19.1% of the time depending on the task.
But here is the thing most people don’t realize. Many of these hallucinations start with bad training data. When the information used to teach an AI is messy, inconsistent, or poorly labeled, the model learns those mistakes. It then repeats them with confidence. That is why high quality data labeling matters so much right now.
Good data labeling helps reduce hallucination rates and builds user trust.

Think of it like teaching a child. If you give a child wrong answers during a lesson, they will repeat those wrong answers later. The same goes for AI models. Clean, accurate labels in the training data mean the AI has a better chance of getting things right.
This is where ai data labeling jobs come in. As AI adoption keeps growing, the demand for people who can carefully label and check training data is surging. These roles are not just about clicking boxes. They are about catching the small errors that can cause big hallucinations later.
So before we dive into how to catch hallucinations, we need to understand what makes them happen in the first place. And it starts with the data. If you want to see just how often AI models still get things wrong, check out Dean Grey’s research on AI uncertainty and human judgment. For a full look at detection methods and prevention strategies, you can Explore Guides that break down how to spot and stop hallucinations before they cause real damage.
The Hallucination–Data Quality Link
Let us look at how bad data leads to those confident but wrong answers. When you think about ai data labeling jobs, it is easy to imagine simple tasks like clicking boxes. But the truth is more serious. Every time a labeler makes a mistake, that error gets baked into the model. The AI learns that wrong information as a true pattern. Then it repeats that pattern with full confidence.
Think about it like this. If you teach a child that 2 plus 2 equals 5, they will believe it is true. An AI model does the same thing with noisy labels. It does not know the label is wrong. It just learns the pattern.
Here is the thing. Different types of hallucinations come from different labeling mistakes.

- Factual hallucinations happen when the model makes up false information. This often traces back to training data where labels contain completely wrong facts. For example, a picture labeled "cat" that is actually a dog.
- Contextual hallucinations occur when the model misunderstands the situation. This happens when labels are unclear or miss important context. For example, labeling a medical image as "healthy" without noting unusual features.
Both types create real problems. According to AI Hallucination Rate Benchmarks 2026, current models still hallucinate between 3.1% and 19.1% of the time depending on the task. That is a huge range, and bad data is a big reason why.
The good news is that small fixes make a big difference. One case study showed that cleaning just 5% of noisy training labels reduced hallucination rates by 30%. That is a massive improvement from a small change. It proves how much cleaner data matters.
If you are already building AI systems or thinking about starting, understanding what is data engineering is a smart move. Data engineers build the pipelines that keep training data clean. They catch labeling errors before those errors reach the model.
For a deeper look at how to spot these mistakes before they cause trouble, check out our complete guide on detection and prevention strategies. It walks you through practical steps to protect your models from bad data.
And if you want to see how even small labeling improvements can change outcomes, read Dean Grey’s research on AI uncertainty and human judgment. His work shows why clean data is your best defense.
Core Principles of Data Labeling
Now that you have seen how bad data causes hallucinations, let’s talk about what makes training data actually good. Strong data labeling is not just about clicking boxes fast. It follows a few core rules that keep your AI reliable.

The first principle is consistent annotation guidelines. Every person working on your labeling project must follow the same set of rules.

If one labeler marks a product image as "clothing" and another calls it "apparel," the model gets confused. A single, clear guidebook stops that. You can think of it like a shared recipe. Everyone follows the same steps to get the same result. Skilled labelers, who are in higher demand than ever according to the 2026 AI data annotation hiring landscape, make this consistency possible.
The second principle is that your label taxonomies must be exhaustive and mutually exclusive. This sounds complex but it is simple. Your list of possible labels must cover every option (exhaustive). And no two labels should overlap (mutually exclusive). For example, if you are labeling customer feedback, do not use "positive" and "happy." Those mean the same thing. Use distinct labels like "positive," "negative," and "neutral." When categories are clean, the model learns sharp boundaries instead of fuzzy guesses.
The third principle is inter-annotator agreement metrics. This is a fancy way of saying you must check if your labelers agree with each other. Use tools like Cohen’s kappa or precision scores to measure agreement. If two people label the same image differently, you have a problem. Low agreement means your guidelines are weak or your taxonomies are broken. Fix that before training your model. This step catches hidden errors that otherwise become hallucinations.
These principles work together. They reduce confusion for humans and for AI. For a deeper look at how to build these systems into your workflow, check out our guide on detection and prevention strategies. It shows you how to apply these rules to real projects.
Understanding what is data engineering also helps here. Data engineers design the pipelines that enforce these labeling standards at scale. They build the systems that catch inconsistencies before the model ever sees them.
Clean data starts with clean rules. And clean rules start with these principles.
If you want more hands-on methods to keep your AI honest, explore our guides and strategies for reducing hallucinations in 2026.
Essential Skills for Data Labeling Jobs
So you understand the principles for clean data. Now what does it take to get hired for this work? Data labeling jobs in 2026 require more than just clicking boxes. The field has changed a lot. Companies now look for people with specific skills that improve data quality from the very start.
**Domain expertise is your biggest advantage.

**
If you know medicine, law, engineering, or finance, you can earn more. A nurse labeling medical scans catches problems a general labeler would never see. A paralegal reviewing legal documents for training data understands subtle differences. The changing landscape of AI data labeling hiring in 2026 shows demand for skilled labelers has exploded. Generalists still find work. But specialists get the best projects and higher pay rates.
Tool proficiency is nonnegotiable.
Most annotation work happens inside specialized software. Platforms like Labelbox, Supervisely, and custom enterprise tools are standard. You need to know bounding boxes, segmentation masks, and classification tags. You should also understand how your work fits into larger pipelines. That is where learning what is data engineering helps. Data engineers build the systems that move your labels into training sets. Knowing this context makes you more useful to employers. It also helps you communicate better with technical teams.
Soft skills set you apart.
Attention to detail is the top trait hiring managers seek. Can you spot tiny differences in images? Can you read text carefully and pick the right label every time? Analytical thinking is just as important. When a label does not fit, ask why. Maybe the category is wrong. Maybe the guidelines need updating. Strong labelers think critically. They do not just click through tasks.
The NACE Job Outlook 2026 report shows a cautious hiring market for new graduates. That means standing out matters more than ever. Having a personal data booklet with your annotation guidelines and quality scores can help you show employers your skills during interviews. Companies like Scale AI also offer certification paths to prove your abilities.
If you want to see how data quality connects directly to AI accuracy, build a custom AI fact checker workflow. It lets you test the difference between good and bad training data.
Master these skills and you will stand out in the growing market for ai data labeling jobs. Companies pay more for labelers who understand the bigger picture. And that knowledge helps reduce AI hallucinations at the source.
Explore more guides and strategies to understand how high quality data improves AI reliability in 2026.
Tools and Platforms for Data Labeling
You have the skills. Now you need the right tools. The data labeling world in 2026 offers more options than ever. And picking the right platform can make or break your work quality.
Let’s look at what is out there.
Image and video annotation tools handle most visual data. Platforms like SuperAnnotate, Labelbox, and Scale AI let you draw bounding boxes around objects, create segmentation masks, and tag images. According to a comparison of the best data labeling tools in 2026, these platforms support everything from simple classification to complex lidar data for autonomous vehicles. If you work with security footage, specialized tools designed for AI security and surveillance give you better results.
NLP and text labeling platforms handle language data. Think sentiment analysis, entity recognition, and text classification. These tools let you highlight words, tag parts of speech, and label intent. They matter a lot for training chatbots and language models that do not hallucinate.
Automated labeling is changing the game.
Here is the thing. Many platforms now use active learning and AI-assisted labeling. The software pre-labels your data, and you only correct mistakes. This cuts manual work by huge amounts. But it requires careful oversight. The top data labeling companies in 2026 emphasize that automation speeds things up but never replaces human judgment entirely. You still need to catch errors the AI makes.
Managed services handle the heavy lifting.
Companies like Appen, Scale AI, and Labelbox offer managed labeling services. They take your raw data, apply trained labelers, and return clean datasets. This works well for teams without internal labeling capacity. A guide on choosing the right data labeling company suggests looking at quality scores, turnaround time, and domain expertise when selecting a partner.
How to pick the right tool for you.
Ask yourself these questions:
- What type of data do you have? Images, text, video, or audio?
- How much volume do you need to label?
- Do you need managed services or just software?
- What quality metrics will you track?
Platforms like SuperAnnotate score 4.9 out of 5 in user reviews for good reason. They combine ease of use with powerful features. And you can always check G2 user reviews for real feedback from other labelers.
The right tool choices lead to cleaner data. And cleaner data means fewer AI hallucinations down the road. If you want to see how tool quality affects AI output, check out our comparison of AI tools that hallucinate the least. It helps you understand why annotation quality matters so much.
Explore more guides and detection methods to keep your AI projects on track in 2026.
Quality Assurance Methods for Labeled Datasets
Picking the right tool is just step one. Here is the real truth. Even the best platform produces garbage if nobody checks the work. Quality assurance (QA) is what separates usable training data from wasted time.
Think of it this way. You would not launch a product without testing it first. Same logic applies to labeled datasets.
Multi-stage QA catches more errors.
Most top performing teams use a three-layer approach. First, automated checks scan for obvious mistakes like missing labels or mismatched formats. Second, random sampling pulls a percentage of labeled items for human review. Third, expert reviewers dig into edge cases and tricky examples.
According to research on data quality metrics for labeled data, these scoring methods compare labeler annotations against expert reviews to quantify quality. This gives you a number you can actually track and improve.
Track the right metrics.
The three big ones are accuracy, completeness, and consistency. Accuracy means the label matches reality. Completeness means every relevant object got tagged. Consistency means the same object gets the same label every time across different labelers.
If one of these metrics drops below your threshold, you know exactly where to focus retraining.
Active learning flags problems early.
This is where smart automation helps a lot. Modern platforms use active learning to spot uncertain labels automatically. The system flags items it is unsure about and sends them straight to human review. This reduces the need to check every single item manually.
For people looking into ai data labeling jobs, understanding QA workflows is a major skill that employers actually look for. It shows you care about quality, not just speed.
When QA is solid, your AI models suffer fewer hallucinations. If you want to dive deeper into building a reliable fact-checking process, check out this guide on how to detect and prevent AI hallucinations. It covers the same quality mindset applied to AI outputs.
Explore Guides for more strategies on keeping your AI project accurate in 2026.
Finding AI Data Labeling Jobs in 2026
Now you know how QA keeps datasets clean. But how do you actually land a role doing this work? The good news is that the demand for ai data labeling jobs keeps growing as more companies build custom AI models.
Start with the right platforms.
The big players in this space include Appen, Clickworker, Scale AI, and Toloka. Each platform connects labelers with companies that need training data. According to a review of human data labeling providers in 2026, these platforms rank among the top options for finding steady work. General freelance sites like Upwork and Fiverr also have labeling gigs, but the pay and consistency vary a lot.
For remote work, check job boards like Indeed too. There are hundreds of data labeling jobs in remote settings posted regularly.
Build a portfolio that proves your skill.
Nobody hires a labeler with zero experience. So you need to show what you can do. Start by completing open source labeling projects. Contribute to competition datasets on platforms like Kaggle. Document your accuracy metrics from those projects. When you apply, share a short sample of your work. This is how you stand out from people who just fill out applications.
The same data quality metrics for labeled data we talked about earlier also help you sell yourself. If you can show 98 percent accuracy on a past project, that speaks louder than any resume line.
Network where the work lives.
This part matters more than most people think. Attend AI conferences, even virtual ones. Join annotation communities on Discord, Reddit, and LinkedIn. Follow leaders at companies like Scale AI and Surge AI. You will hear about new projects before they hit the public job boards.
The best ai data labeling jobs often come through referrals, not applications.
Understanding how labeling connects to AI reliability is a big advantage. If you are curious about why accuracy matters so much for AI outputs, check out this guide on how to detect and prevent AI hallucinations. It explains exactly why your labeling work matters in the bigger picture.
For more strategies on building a career in this space, Explore Guides covering detection methods, prevention strategies, and industry insights.
Building a Career in Data Labeling
You might think of data labeling as just an entry level gig. But the truth is, it can be a real stepping stone to something bigger. Many people who start with ai data labeling jobs move on to roles in data science or machine learning engineering.
That is a big deal.
The biggest players in this space, like companies such as Scale AI among the top human data labeling providers in 2026, hire labelers who later become data scientists. Why? Because you learn how AI actually learns. You spot patterns. You understand data quality. That is valuable knowledge.
Certifications make a difference.
You can speed up your career growth by getting certified in data annotation and quality assurance. These certifications show employers you know how to do the job well. They add real credibility to your resume. Some of the top data labeling tools even offer their own training programs. Completing those can open doors.
Think about long term growth.
Here is what a typical path looks like.
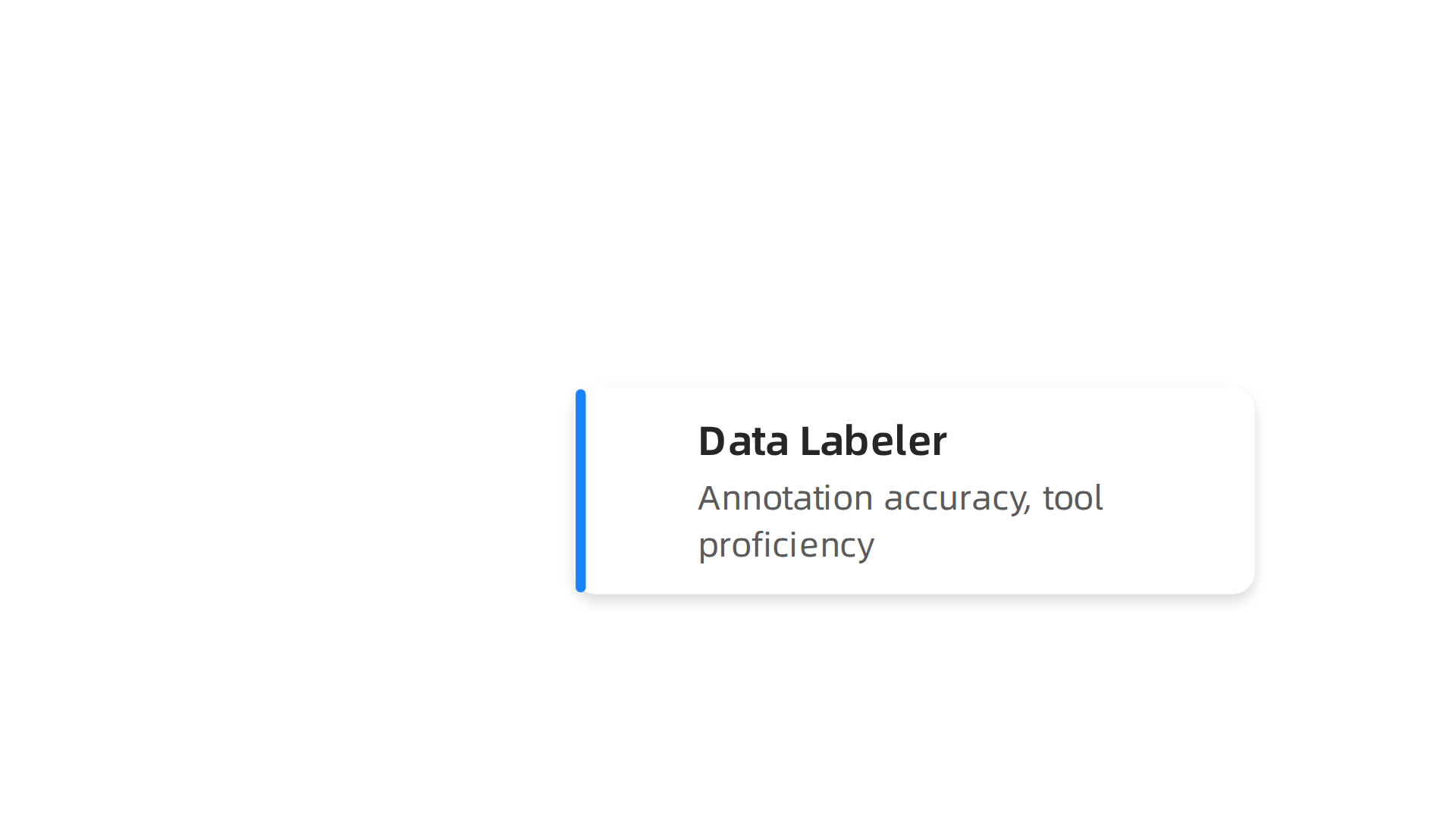
| Role | Skills Gained | Next Step |
|---|---|---|
| Data Labeler | Annotation accuracy, tool proficiency | QA Specialist |
| QA Specialist | Error detection, feedback loops | Team Lead |
| Team Lead | Project management, training others | Data Scientist or ML Engineer |
Moving from labeler to QA specialist is common. You learn to catch mistakes and improve processes. From there, you can become a team lead. And after that, you might move into data science or ML engineering.
The work you do also ties directly to AI reliability. If you want to understand why your high quality labels help prevent huge AI mistakes, check out this guide on how to detect and prevent AI hallucinations. It shows exactly how your labeling work builds safer AI.
For more detailed career strategies and industry insights, Explore Guides covering detection methods, prevention strategies, and long term career paths.
Ethical and Bias Considerations in Labeling
When you take on ai data labeling jobs, you are teaching AI how to understand the world. But here is the thing. If your labels contain hidden bias, the AI learns that bias too. And that can cause real harm.
Research from the Brookings Institution shows that algorithm bias in AI systems can hurt real people through unfair decisions. Biased labels lead directly to biased models. That is why fairness is not just an extra step. It is the foundation of trustworthy AI.
Where does bias come from?
Bias often starts with the people doing the labeling. If every labeler shares the same background, they might miss important perspectives. Different cultures, genders, and life experiences see the world differently. That is why diverse annotator teams matter so much.

As Alation explains, the labels you create directly shape how AI models behave. So diversity in your team is not optional. It is essential for fairness.
New rules in 2026.
Governments are paying close attention now. The European Union’s AI Act requires companies to document their labeling processes. This means proving your training data was labeled fairly and without hidden bias. In medical imaging, for example, bias in AI must be addressed to protect patients, according to research in PMC. Similar rules are appearing in other countries too. The SmartDev guide on AI bias notes that organizations must use diverse datasets and ensure transparency to meet these standards.
Simple steps for fair labeling.
Here is what you can do to make a difference:
- Use a diverse team of annotators with different backgrounds
- Write clear guidelines that cover sensitive topics and edge cases
- Run regular fairness audits on your labels
- Document every step of your labeling process
These steps do two things. They make AI safer for everyone. And they make you more valuable as a labeler.
Companies in 2026 are actively looking for people who understand ethics. If you want to see how your high quality labels help prevent bigger AI problems like hallucinations, check out this guide on how to detect and prevent AI hallucinations. Your work is the first line of defense.
For more strategies on building ethical AI systems you can trust, Explore Guides covering detection methods and prevention strategies.
Summary
This article explains why high-quality data labeling is one of the most important levers for reducing AI hallucinations and building trustworthy models. It links messy or inconsistent labels to both factual and contextual hallucinations, then lays out core labeling principles—consistent guidelines, exhaustive taxonomies, and inter-annotator agreement—that stop errors before they reach models. The piece covers the real skills employers want in 2026, from domain expertise to tool proficiency and QA know-how, and it compares annotation platforms, automation trends, and managed services that speed work without sacrificing accuracy. You’ll also get practical QA methods, metrics to track (accuracy, completeness, consistency), hiring tips for finding labeling work, and a roadmap for career growth from labeler to data scientist. Finally, the article highlights ethical and bias issues in labeling and gives concrete steps to reduce unfair outcomes, making your datasets both safer and more valuable for production AI.