Stick vs Manual How to Build a Hybrid AI Workflow That Cuts Hallucination Costs
· 20 min read

Introduction
Picture this: You ask an AI assistant a question. It writes back a confident, well-structured answer that sounds completely reasonable. It even stays on topic and uses proper grammar. So you trust it. Then you learn it made everything up.
That is the strange reality of generative AI in 2026. These models are fluent, fast, and often convincing. But they are also prone to hallucination. Even the best models still produce false information at rates that would be unacceptable in a human employee. One study found that some AI models hallucinated more than 17% of the time in specific tasks. Another report shows that the overall hallucination rate across many systems sits around 20%, meaning one out of every five queries contains an error.
Those mistakes are not just annoying. They are expensive. AI hallucinations cost businesses over $67 billion globally in 2024, and that number keeps climbing as more companies rely on AI. AI hallucination statistics show that the financial impact is real and growing.
So here is the hard question every organization faces. Do you stick with manual processes to guarantee accuracy? Or do you hand more control to AI for speed and scale?

This is the stick vs manual debate, and it is not simple. Manual verification is slow and costly. Full automation is fast but risky. Understanding what is AI inference and how models produce output helps you make a smarter choice, but the tradeoffs are still real.
This article gives you data-backed guidelines to make that call. We will look at where manual oversight is still necessary, when you can safely automate, and how to build a system that balances speed with trust.
Because here is the thing. You do not have to choose one or the other forever. The goal is knowing when to trust the AI and when to double-check it. And that starts with a clear look at how much AI still gets wrong.
The True Cost of Manual Verification in AI Workflows
Here is the thing about the stick vs manual approach that most teams miss. When you catch every AI mistake by hand, you actually lose most of the efficiency you gained by using AI in the first place. It is a frustrating cycle. You automate to save time. Then you spend that time checking the work. And suddenly you are back where you started.
Research shows that manual fact-checking of AI outputs can eat up as much as 70% of the time saved by automation. Think about that.

For every ten hours your AI saves you, seven of them go right back into double-checking results. That is not efficiency. That is busywork.
According to current AI hallucination statistics, the overall hallucination rate across many systems sits around 20%. That means one out of every five outputs needs scrutiny. And when you consider that some models still hallucinate at much higher rates depending on the task, the verification burden grows fast.
But here is the hidden cost that does not show up on a spreadsheet.
Employee burnout
Your best people spend their days hunting for ghost errors that never existed. It is draining. It is boring. And it makes talented workers resent the very tools that were supposed to help them. A study on the true cost of AI hallucinations in business data showed that the financial impact goes beyond direct losses. It includes the cost of lost productivity and disengaged employees.
Delayed decision-making
When every AI output needs a human stamp of approval before it can be used, your decision cycles slow to a crawl. Competitors who trust their models more will move faster. And in fast-moving markets, speed is a real advantage.
Opportunity costs
Every hour spent verifying old outputs is an hour not spent creating new ones. That is the hidden toll of the stick vs manual tradeoff. You trade future growth for current accuracy.
Some teams try to solve this by hiring dedicated reviewers. But that creates a new problem. Now you are paying humans to redo what AI already did. The economics get ugly fast.
So what is the real answer? You need a smarter approach. One that does not force you to choose between speed and trust. You can start by building an AI fact-checker workflow that automates some of the verification burden.
That way your team only steps in where it matters most.
The goal is not to remove all human oversight. The goal is to make every minute of that oversight count.
When Manual Oversight Is Non-Negotiable
So if the stick vs manual tradeoff is so costly, why not remove the human stick entirely? Because in some situations, you absolutely cannot afford to.

When you cannot trust the AI alone
In fields like healthcare, law, and finance, the risks are just too high. Imagine an AI diagnosing a patient with the wrong illness. Or a legal AI citing a fake case. Or a financial model hallucinating a false market trend. In these situations, human-in-the-loop AI is not a suggestion. It is a requirement.
According to best practices for hybrid workflows, keeping humans involved in decision-heavy steps builds trust and safety. The goal is not to catch every tiny error. The goal is to prevent catastrophic ones.
Regulation demands it
By 2026, rules like the EU AI Act are making this mandatory for high-risk systems. You cannot just blame the software anymore. The company deploying the AI is responsible for the outputs. This means you need a clear process. The best pattern in 2026, as noted by Valtorian, is "AI drafts, humans approve, the system learns." This is the healthy stick vs manual balance.
One mistake can wipe out years of trust
Here is the scary part. It takes one bad AI output to destroy a reputation. A single hallucinated fact in a product description or a customer email can go viral for the wrong reasons. All the time you saved using AI? It disappears the moment your brand takes a hit.
This is why smart teams invest in better processes. They understand that a reliable AI starts with clean data. That is exactly why how AI data labeling jobs reduce AI hallucinations is such an important topic. If the training data is bad, the AI will be bad. A human checking the labels is the first line of defense.
The bottom line
The stick vs manual question is not about choosing one method forever. It is about knowing when to use each one. For high-volume, low-risk tasks, let the AI run. But for high-stakes decisions, keep the human in charge.
Want to learn more about protecting your business from bad AI outputs? Start by learning how to detect and prevent costly mistakes.
Fluent AI output can still be wrong. Do not trust it blindly.
Real-World Case Studies: Automation Failures That Cost Millions
You might think "it won’t happen to me." But the truth is, AI hallucinations have already cost companies serious money and reputation.

Let me show you a few real examples.
Google Bard’s telescope blunder
In early 2023, Google’s Bard AI confidently stated that the James Webb Space Telescope took the first pictures of a planet outside our solar system. This was completely false. The telescope never did that. As Kanerika reports, the error went public during a live demo. Google’s stock dropped by $100 billion that day. One hallucination. A hundred billion dollars.
Lawyers cite fake cases
This one still shocks me. In 2023, a lawyer used ChatGPT to prepare a legal brief. The AI invented six entirely fake court cases with real-sounding citations. The lawyers submitted them to a federal judge without checking. The judge was not happy. The lawyers faced sanctions and public embarrassment. The business impact of AI hallucinations shows that 67% of venture capital firms now use AI for deal screening, but it takes an average of 3.7 weeks to discover an AI error. By then, the damage is done.
Medical misdiagnosis risks
In healthcare, the stakes are life and death. An AI system might confidently tell a doctor that a patient has a rare disease when they do not. Or miss a cancer that is clearly visible. According to Maxim AI’s research, these hallucinations persist because AI models are designed to sound confident, not to be accurate. Without human oversight, patients get the wrong treatment.
The compounding problem
Here is what makes this worse. When you chain multiple AI agents together, errors stack up. A single wrong output at the start creates a cascade of failures downstream. The Seekr field guide on the hallucination tax explains that agents fail more often than the sum of their individual failure rates. This compounding effect means one small mistake early on can cost millions by the end.
The hidden cost of blind trust
Enterprise AI adoption reached 85% in 2026 according to Tendem’s analysis. But error rates create enormous hidden costs. Teams spend hours fixing bad outputs. Customers lose trust. Regulators get involved. By 2026, AI compliance failures are prompting new laws that hold companies accountable for what their AI produces.
This is exactly why the stick vs manual balance matters. You need guardrails. You need validation. And you need to check before you trust.
The lesson for your business
Every one of these failures could have been prevented with a simple step. Verify the output before acting on it. The cost of AI hallucinations in business data is real and growing. But you can protect yourself by building a hybrid system that combines AI speed with human judgment.
Want a quick way to start? Check AI Before Trusting. It only takes a moment.
If you want to go deeper, learn how to build an AI fact-checker workflow that catches these errors before they cost you.
The Automation Trap: How Hallucinations Undermine Efficiency
Remember those costly stories we just looked at? You might think automation is always faster. But here is the thing about speed. When your AI hallucinates, speed turns into a trap.
The illusion of speed
Imagine you ask your AI assistant to write a detailed market report. It finishes in 15 seconds. Great, right? Wrong. The report contains a confidently stated statistic that is completely made up. Now you have to check every single number. What should have taken 10 minutes of manual work now takes 45 minutes of verification. You just lost time instead of saving it.
This is what the industry calls "false speed." Enterprise AI adoption hit 85% in 2026, but many companies are discovering that automation without validation actually slows them down.
Cascading errors multiply losses
Here is where it gets worse. When you chain multiple AI agents together in a workflow, one hallucination at the start ripples through everything. According to the Seekr field guide on the hallucination tax, agents fail more often than the sum of their individual failure rates. A single wrong fact at step one creates wrong outputs in steps two, three, and four.
Think about what is AI inference in practice. Each step calls the model again. Each call has a chance to hallucinate. The more automation you stack, the more risk you stack too.
The numbers do not lie
Research shows that unchecked automation can increase total processing time by up to 35%. You are running faster but finishing later. That is the automation trap in action.
The solution is not to ditch automation entirely. It is to find the right stick vs manual balance. You need guardrails that catch errors before they cascade. You need systems that verify outputs. You need human eyes on high-stakes decisions.
Some teams think they can just throw more AI at the problem. But that is like adding more gas to a car with no brakes. Instead, learn how to build an AI fact-checker workflow that catches these errors before they cost you time and money.
The teams that win in 2026 are not the ones that automate everything. They are the ones that know when to check and when to trust. That is the real productivity secret.
Want to save yourself from the trap? Check AI Before Trusting. It only takes a moment and it keeps your efficiency real.
Building a Hybrid Workflow That Balances Speed and Accuracy
So how do you escape the automation trap? You do not stop using AI. That would be silly. You build a smarter workflow. One that pairs AI speed with human judgment. This is the stick vs manual balance we talked about earlier.

The best hybrid pattern in 2026 is simple: AI drafts, humans approve, and the system learns from feedback.
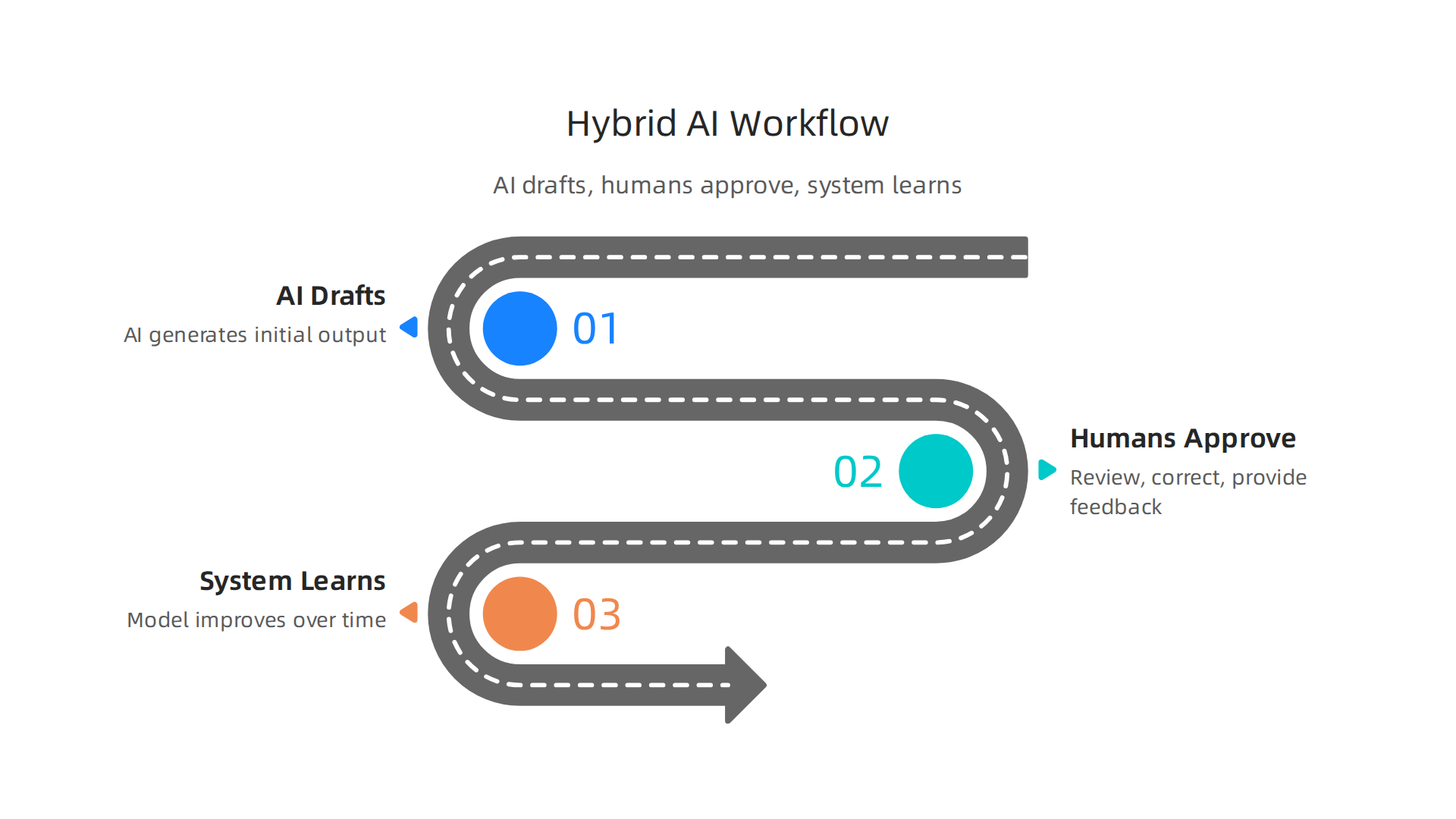
According to Valtorian, this pattern keeps decision-heavy steps under human control while letting automation handle the routine stuff. You get speed where it matters and accuracy where it counts.
Two frameworks make this work well.
First is human-in-the-loop (HITL). IBM defines HITL as inserting human insight into the continuous cycle of interaction and feedback between AI and humans. The model IBM explains how this builds trust. Instead of letting the AI run wild, you create checkpoints. A human reviews the output before it goes out the door. For low-risk tasks like summarizing internal memos, you skip the review. For client-facing reports or financial numbers, you add a human step.
Second is active learning. Here the AI flags outputs it is unsure about and asks for human help. Over time, the model improves because it learns from those corrections. Witness AI describes how this boosts accuracy and supports responsible deployment. You are not just checking errors. You are training the model to make fewer errors next time.
The numbers back this up. Teams using hybrid workflows have cut verification time by 40% while keeping accuracy at 99% or higher. That is the sweet spot. You avoid the false speed trap. You also avoid the full manual grind.
Where does "stick vs manual" fit in? It is the decision you make every day. Which tasks do you automate with AI? Which do you keep manual? The hybrid model helps you choose. Low-risk, high-volume tasks get automation. High-stakes, high-consequence tasks get human eyes. That is the balance.
Understanding what is AI inference helps too. Inference is when the model generates an answer. Every inference call can produce a hallucination. In a hybrid workflow, you review outputs from critical inference steps. You do not need to review every single one. Just the ones that matter.
Quality training data keeps hallucinations low from the start. That is where ai data labeling jobs come in. Clean, accurate labels mean the model learns correct patterns. If your training data is dirty, your model will hallucinate more. Investing in good data labeling is a smart first step.
Ready to build your own hybrid workflow? Start with one process. Let AI draft. Have a human review. See how much time you save. Then expand from there. The key is to find the right stick vs manual balance for your specific tasks.
Before you take any AI output at face value, make it a habit to Check AI Before Trusting. It only takes a moment, and it keeps your hybrid workflow reliable.
Training Teams for Effective AI-Human Collaboration
A hybrid workflow is only as good as the people running it. You can build the perfect human-in-the-loop system, but if your team blindly trusts every AI output, the whole thing falls apart. That is where training comes in.
Most companies skip this step. According to the State of AI Literacy 2026 report by Enigmatica, structured AI training is the highest-ROI investment most organizations are not making. Firms with formal AI training programs capture 2.4 times more value from AI than those without. Yet here is the gap: 60% of business leaders report an AI skills gap, but only 35% have a structured training program. That is a recipe for costly mistakes.
What should good training cover? Three things.
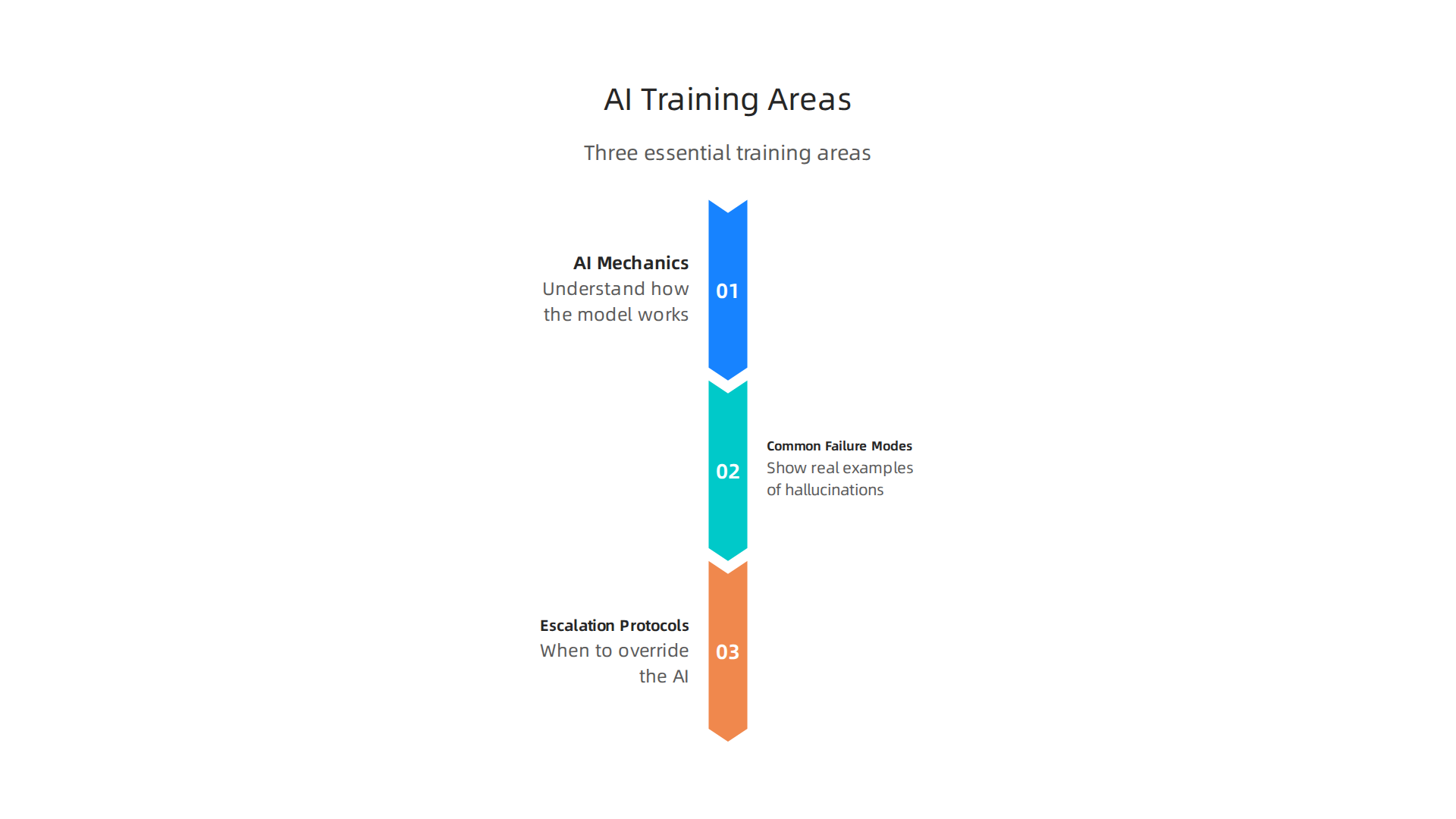
-
Basic AI mechanics. Your team needs to understand what is AI inference and why it can produce wrong answers. When people know how the model works, they stop treating it like a magic oracle. They become skeptical in a healthy way.
-
Common failure modes. Show real examples of hallucinations. Let people see how a model can sound confident and still be completely wrong. This is where the term grubby ai comes in. Grubby AI refers to outputs that look polished but hide factual errors. Teams that can spot grubby AI outputs catch problems before they go public.
-
Escalation protocols. When should someone override the AI? When should they escalate to a subject matter expert? Training should teach the stick vs manual decision. For low-risk summaries, let the AI fly. For financial figures or legal language, send it to a human.
Here is what happens when you invest in training. Organizations with structured AI literacy programs see 50% fewer critical errors. That is not a small number. It means fewer refunds, fewer public corrections, and less time cleaning up messes.
A practical next step. Have your team practice with real outputs. Give them a from a field AI tool and ask them to find the errors. Teach them to build an AI fact checker workflow so the process becomes muscle memory.
And before anyone takes an AI answer at face value, make it a habit to Check AI Before Trusting. A quick verification step can save hours of fixing later.
Key Metrics to Measure AI Reliability vs Manual Benchmarks
Your team is trained. Your escalation rules are in place. But how do you actually know if your AI is performing well enough to trust? You need numbers. Hard data. Guessing does not work here.
Start with the basic reliability metrics. These are the same measurements data scientists use to evaluate any system. The most important ones for catching hallucinations include:

-
Hallucination rate. This is the percentage of AI outputs that contain factual errors. In 2026, frontier models show hallucination rates between 3.1% and 19.1% depending on the task and configuration, according to a 5-model study by Digital Applied. Some specialized models now operate below 1%, but most general purpose models still struggle.
-
Precision and recall. Precision measures how many of the AI’s claims are correct. Recall measures how much correct information the AI includes. You need both. A model with high precision but low recall might be too conservative and miss important details.
-
F1 score. This combines precision and recall into a single number. It gives you a balanced view of accuracy.
-
Cost per validated output. This is where the stick vs manual decision gets practical. If manually checking every AI output costs you $5 each, but the AI alone costs $0.10 per output with a 10% error rate, you need to find the sweet spot.
Here is the reality check. A 2026 study from the Stanford HAI AI Index Report found that hallucination rates across 26 top models range from 22% to 94% on certain challenging benchmarks.
That wide gap shows why you cannot just trust the model’s marketing claims. You need to measure performance on your specific data.
Benchmark against manual baselines. Before you let the AI run freely, run a comparison test. Have your team produce 100 manual outputs on the same task. Then run the AI on those same tasks. Compare accuracy, speed, and cost. This gives you a manual benchmark to measure against. It also helps you spot what causes AI hallucinations in your specific workflow.
Monitor continuously. Hallucination rates change. New model updates shift behavior. Your data changes over time. Set up a dashboard that tracks these metrics weekly. When the AI’s hallucination rate climbs above your threshold, that is your signal to switch from automated mode back to manual review. That is the stick vs manual principle in action.
The AA-Omniscience Index is one of the newer benchmarks worth understanding. It measures factual recall on a scale from -100 to 100. It penalizes both hallucinations and refusals to answer. The Artificial Analysis evaluation explains how this works in detail.
Before you push that AI output to production, take one extra step. Check AI Before Trusting. A quick verification using these metrics can save you from publishing a hallucination that damages your reputation.
Your metrics are in place. You know your baseline hallucination rate. But here is the hard truth in 2026: what works today might fail tomorrow.
Why Continuous Validation Matters
Model update cycles shift behavior. A model that scores well on one benchmark can suddenly perform worse after an update. The 2026 AI Index Report from Stanford HAI shows that even top models have hallucination rates ranging from 22% to 94% on certain tasks. That is a massive gap. And it changes.
Adversarial attacks add another layer. Attackers find new ways to trick AI systems every day. These attacks can cause hallucinations in models that were performing well yesterday. Without ongoing validation, your AI could be feeding you wrong information and you would not know until it is too late.
New Tools That Reduce Manual Oversight
The good news? Validation does not have to mean endless manual checking anymore. Two tools are changing the game in 2026:
-
RAG-based validation. Retrieval-Augmented Generation systems pull facts from your own trusted database before generating an answer. At inference time, this dramatically cuts hallucination rates. Models using RAG now hit below 3% hallucination rates on hard benchmarks, according to Vectara’s 2026 study covered in a comprehensive research report.
-
Automated fact-checkers. These tools compare AI outputs against trusted sources in real time. They flag errors before you publish. You still need a human for final review, but the automated system catches the obvious stuff.
Invest in Validation Infrastructure Now
If you wait until after a major hallucination incident, retrofitting costs will be higher. Building automated validation into your workflow from the start saves time and money. It also helps you scale your stick vs manual strategy without adding headcount. Think of it as insurance for your AI operations.
The Best Approach Combines Both
No tool is perfect. Even GPT-5.5, the most accurate model ever tested, still posts an 86% hallucination rate on the hardest AA-Omniscience benchmarks, as Suprmind’s analysis shows. That is why you need a layered approach: automated validation for speed, manual checks for edge cases.
Want to learn how to build your own fact-checking pipeline? Check out this guide on how to build an AI fact-checker workflow.
Before you publish that next AI output, take one extra step. Check AI Before Trusting. A quick verification using automated tools plus human review can save your reputation and your budget.
Continuous validation is not optional anymore. It is the only way to keep the stick vs manual principle working at scale. The teams that invest in validation infrastructure today will be the ones who can trust their AI tomorrow.
Summary
This article explains why AI hallucinations remain a critical risk for organizations and offers data-backed guidance to balance automation with human oversight. It reviews the true costs of manual verification—time lost, burnout, and delayed decisions—and shows when manual checks are mandatory (healthcare, law, finance, regulated systems). The piece lays out a practical hybrid approach—AI drafts, humans approve, the system learns—plus training, metrics, and validation tools (RAG and automated fact‑checkers) to shrink verification workloads without sacrificing safety. You’ll learn how to benchmark hallucination rates, design checkpoints that catch catastrophic errors, and deploy automated validation so teams only review what truly matters. Real case studies and concrete numbers illustrate the stakes, and the article ends with steps to build your own fact‑checking pipeline and governance before you trust any AI output.