What Causes AI Hallucinations and How Anthropic AI Fights Them
· 21 min read

Introduction
Imagine asking an AI assistant a simple question about your business data and getting back a confident, polished answer that is completely wrong.

That is not a rare bug. It happens all the time.
In 2026, AI hallucinations remain one of the biggest roadblocks standing between companies and real trust in artificial intelligence. According to the Stanford HAI 2026 AI Index Report, hallucination rates across 26 top models range from 22% to more than 50% depending on the benchmark.
That is a staggering number. When nearly one in four responses from a leading model could be inaccurate, relying on AI for important decisions becomes risky fast.
The costs go beyond embarrassing mistakes. A study by Forrester found that the average annual cost per employee just for verifying and fixing hallucinated outputs sits at $14,200. Multiply that across a team and you start seeing real damage to the bottom line. Legal research tools are not safe either. Lexis+ AI and Ask Practical Law AI each hallucinated more than 17% of the time in a recent study.
So why do large language models keep making things up? The root causes are surprisingly simple once you understand how these models work.

They do not know what they know versus what they only believe. They guess from patterns. And without strong guardrails, they confidently present guesses as facts.
Here is where things get interesting. Anthropic AI has taken a different path with its Constitutional AI framework. Instead of just training models to be smarter, this approach teaches them a set of rules and values to follow. It is like giving the AI an internal compass. Early results suggest this method cuts hallucination rates significantly while keeping the model useful.
Understanding the real causes of AI hallucinations is the first step. The second step is knowing which tools and techniques actually work to stop them. If you want a complete breakdown of practical detection and prevention methods, check out our guide on how to detect, prevent, and avoid costly mistakes with AI hallucinations.
Let us walk through what causes these errors, why Anthropic AI offers a fresh solution, and how you can protect your work from the hidden dangers of AI that sounds a little too sure of itself.
What Are AI Hallucinations?
Put simply, an AI hallucination is when a large language model (LLM) gives you information that looks correct but is actually false or completely made up. Here is the thing. The model does not know it is wrong. It delivers the bad information with total confidence because it is just guessing the next most likely word based on patterns in its training data. Sometimes that guess is wildly inaccurate.
These errors come in all sizes. A small hallucination might be giving you the wrong date for a historical event. A big one can be far more dangerous. For example, there are real court cases where lawyers used AI to write legal briefs, and the model completely invented fake court rulings and citations. A database of AI hallucination cases in law from Damien Charlotin tracks these serious real world events. It shows just how easily blind trust in AI can backfire.
So how common are these mistakes in 2026? It depends on the model and the task. The Stanford HAI 2026 AI Index Report found that hallucination rates across 26 top models range from 22% to more than 50% depending on the benchmark. Even the best models can be wrong more than one out of every five times. The Vectara Hallucination Leaderboard tracks how often models make mistakes when summarizing facts. Some models hallucinate less than 5% of the time, while others fail at rates above 20%.
This problem costs businesses a lot of time and money. A study by Forrester found that the average annual cost per employee just for checking and fixing hallucinated outputs sits at $14,200.
This is exactly why the anthropic ai safety approach has gotten so much attention. Instead of only training a model to be smarter, Anthropic uses a method called Constitutional AI. It gives the model a set of internal rules to follow. This directly helps with the root cause of hallucinations, which is that models do not know what they truly know versus what they only believe.
Spotting these errors on your own can be tough. One helpful method is running a red teaming exercise, where you test the AI by asking tricky questions to see where it breaks. You can also use AI detectors that look for inconsistencies in the output. Understanding what AI detectors look for gives you a big advantage.
Want to see how different models compare when it comes to accuracy? Check out our detailed comparison of the AI tools comparison that reveals which platforms hallucinate least. It is a great next step if you want to choose the safest tool for your work.
Types of AI Hallucinations
Not all AI hallucinations are the same. Knowing the difference between them helps you catch mistakes faster and choose the right fix. Researchers group these errors into two main types: intrinsic and extrinsic.

Understanding both is key to managing AI risk in 2026.
Intrinsic hallucinations happen when the AI twists the source material you gave it. Say you feed it a contract from June 1. An intrinsic error would be if the AI says the contract was signed on July 1. The details come from your input, but they are wrong. These errors are often easier to catch because you can compare the output directly to the source. A guide from Lakera explains that these are usually simpler to detect since the original data is right there to check.
Extrinsic hallucinations are far more dangerous. Here the AI adds information that was never in the source at all. It just invents facts out of thin air. A 2026 research report found that legal AI tools like Lexis+ AI hallucinate more than 17% of the time. They create fake court cases and rulings that sound completely real but do not exist. This type of error can ruin a legal brief or a business report without anyone noticing at first.
Both types cause problems, but the severity differs. Factual errors (wrong dates, names, or statistics) hurt your credibility the most. Non-factual errors (formatting issues or inconsistent logic) can confuse your audience and slow down your work.
This is why the anthropic ai safety approach focuses on giving models clear internal rules. When a model understands what it truly knows versus what it only believes, it is far less likely to invent false information.
The best defense starts with knowing what to watch for. If you want to build a system that catches both types of errors automatically, check out our guide on how to build an AI fact-checker workflow to catch these costly mistakes before they reach your audience.
Real-World Consequences and Business Impact
You publish an AI generated blog post. A customer spots a made up statistic. Within hours, someone shares it on social media. Your brand now looks sloppy or dishonest. That is brand damage, and it takes years to fix.
In regulated industries, the stakes are even higher. Legal AI tools like Lexis+ AI hallucinate more than 17% of the time according to a 2026 study.

Imagine a lawyer filing a brief with a fake court case. That can lead to sanctions, malpractice claims, and lost licenses. The same risk applies in healthcare and finance. A hallucinated drug interaction or a wrong quarterly earnings figure can cause real harm.
Then there is the hidden cost. Every small mistake forces you to check and recheck. A 2025 Forrester study quoted by Tendem found that businesses pay an average of $14,200 per employee each year just to verify AI outputs. That is time your team could spend on actual work.
The Stanford 2026 AI Index report shows that hallucination rates across 26 top models range from 22% to over 50%. Even the best models get things wrong. That is why companies investing in safety like the teams behind anthropic ai focus on red teaming exercises and continuous monitoring. A proper red teaming exercise helps you find weak spots before attackers do.
If you want to protect your business, you need systems that catch mistakes automatically. Attackers are already weaponizing AI hallucinations in cyber breaches. Learn how they do it and how to stop them in our detailed guide on how attackers weaponize AI hallucination attacks for cyber breaches.
The Technical Roots of Hallucinations
So why do these hallucinations happen? It helps to look under the hood. Large language models work by predicting the next word based on patterns in their training data. They don’t really know what is true. They just know what sounds likely. That is the core problem.
A 2026 research paper from Arxiv categorizes hallucination sources into three main areas: model factors, data factors, and context factors. This breakdown helps us design better fixes. Instead of guessing, we can target the actual cause.
One big cause is gaps in the training data. When the data is sparse, contradictory, or low quality, the model has no solid foundation to build on. A Duke University blog from early 2026 notes that hallucinations arise when the data is more sparse or low quality. Think of it like a student who only studied half the textbook. They will guess on the rest and often guess wrong.
Another factor is how the model is built. Different architectures and decoding strategies change how likely a hallucination is. The OpenAI team has discussed how models produce overconfident, plausible falsehoods. The model does not know when it is wrong. It just keeps talking with confidence.
Understanding these technical roots is the first step toward designing real mitigations. For example, a red teaming exercise can expose weak spots caused by data gaps or model architecture. When you know what do AI detectors look for, you can build better safeguards.
If you want to learn how to catch these errors before they cause damage, check out our guide on how to build an AI fact checker workflow to catch costly hallucinations. It walks you through a practical system that works in 2026.
Data Gaps and Model Uncertainty
The simplest way to think about data gaps is like a puzzle with missing pieces. The model has to guess what goes in those empty spots. That is where trouble starts.
A Duke University blog from early 2026 confirms that hallucinations often happen when the training data is sparse, contradictory, or low quality. The model has no solid facts to rely on. So it makes something up instead.
Here is the scary part. The model does not know it is guessing. It sounds totally confident. A recent survey from ACM confirms that data factors are one of the three main causes of hallucinations in large language models. The model produces plausible falsehoods because it was trained to predict likely words, not to check if they are true.
This is where model uncertainty becomes a real problem. The model cannot say "I don’t know." It just generates an answer that seems right. Companies like Anthropic AI are working on ways to help models know when they are unsure. One approach is calibration techniques. These methods measure how confident the model really is about its output. If the confidence score is low, you know to double check the answer.
Understanding these data gaps is a big step toward catching hallucinations early. That is exactly what a red teaming exercise does. It pushes the model into its weak spots to find where data is missing or uncertain. If you want to know what do AI detectors look for, this is one of the main signals they flag.
Deepening your understanding of data infrastructure can also help. Check out our guide on the data engineer roadmap 2026 to see how better data pipelines reduce hallucination risks at the source.
The Role of Temperature and Sampling
Here is something most people do not know. Every time you ask an AI a question, you are turning a dial. It is called temperature. And that dial decides how creative or how boring the answer sounds.
A higher temperature setting makes the model pick more surprising words. That sounds fun. But it also means the model is more likely to guess wrong. A 2026 guide from Lakera AI explains that increased randomness from higher temperature settings directly raises the risk of hallucinations. The model starts chasing interesting words instead of accurate ones.
So how do you fix this? Two sampling methods help a lot.
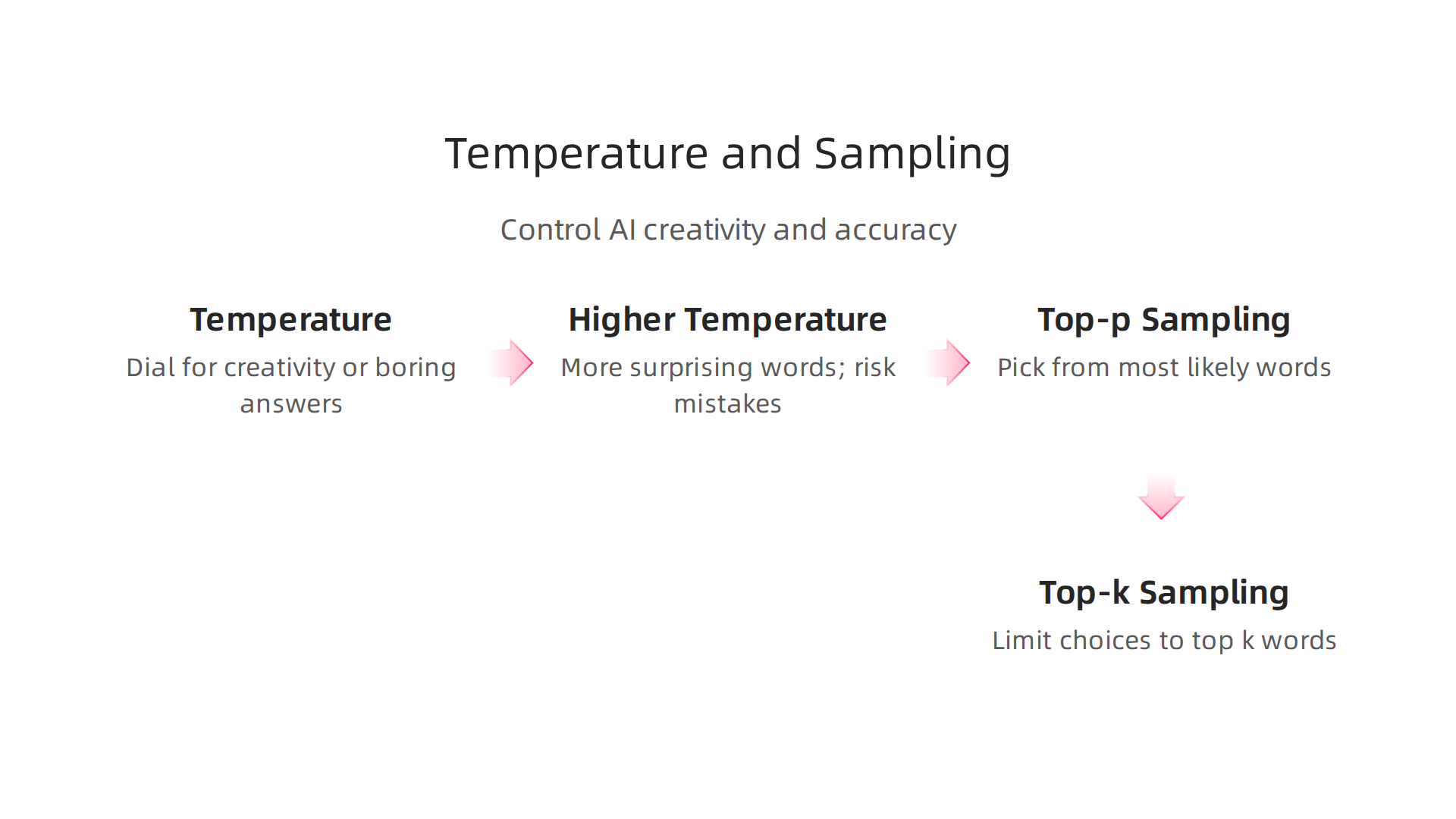
Top-p sampling (also called nucleus sampling) tells the model to only pick from the most likely words until their combined probability hits a set number. Top-k sampling simply limits the model to the top k most likely next words. Both techniques cut out the weird, low-probability guesses that cause hallucinations.
But here is the catch. The right setting depends on what you are doing.
If you are writing a poem, you want higher temperature. If you are asking for a medical fact, you want it as low as possible. The same model can be safe or risky based on one simple setting.
Want to see which platforms let you control these settings well? Check out our comparison of top AI platforms in 2026 that actually reduce hallucination risk. Understanding temperature and sampling is one of the easiest ways to prevent false outputs without changing the model itself.
Anthropic AI’s Constitutional AI and Hallucination Mitigation
So we just talked about dialing down temperature and using sampling tricks. But what if you could build the rules for honesty right into the model from the start? That is exactly what Anthropic AI did with its approach called Constitutional AI.
Instead of just fixing bad answers after they happen, Anthropic trains its model, Claude, with a written constitution. This document spells out the values and behavior Anthropic wants Claude to follow. It is not a secret list either. In early 2026, Anthropic published an updated version of Claude’s constitution so anyone can read it. The constitution tells Claude things like “be helpful” and “don’t make things up.” But here is the clever part. Claude uses those rules during training to teach itself which behaviors are good and which are harmful.
Here is how it works in practice. During a special training step, Claude generates responses and then scores them against the constitution. If a response contains a hallucination or something harmful, the model learns to avoid that path. This is different from the old method of just having humans label good and bad answers. Constitutional AI lets the model act as its own critic, which scales much better and catches more subtle problems.
A 2026 risk report from Anthropic explains how this process helps reduce dangerous outputs. By embedding safety principles deep into the model’s training, the model learns to avoid fabrications even when it does not know the answer. Instead of guessing, Claude learns to say “I am not sure” or ask for clarification. That is a huge win for stopping hallucinations at the source.
How does this compare with other safety methods? Some companies rely on red teaming exercises where experts try to break the model. That is like testing a lock after it is installed. Constitutional AI is more like designing the lock to be unpickable from the start. Both are useful, but embedding rules early catches more issues before they ever reach users.
For anyone building AI systems, understanding the constitution behind Anthropic AI is a great first step. If you want to compare how different models handle trustworthiness, check out our guide to the top AI platforms in 2026 that actually reduce hallucination risk. Knowing what goes into training helps you choose the right tool for the job.
Practical Strategies for Detecting and Reducing Hallucinations
Now that you have seen how models like Anthropic AI build honesty into their training, let us look at what you can do right now. No single trick catches every hallucination. But when you combine a few proven methods, you get much closer to reliable AI output.
Here are three strategies that work best together.
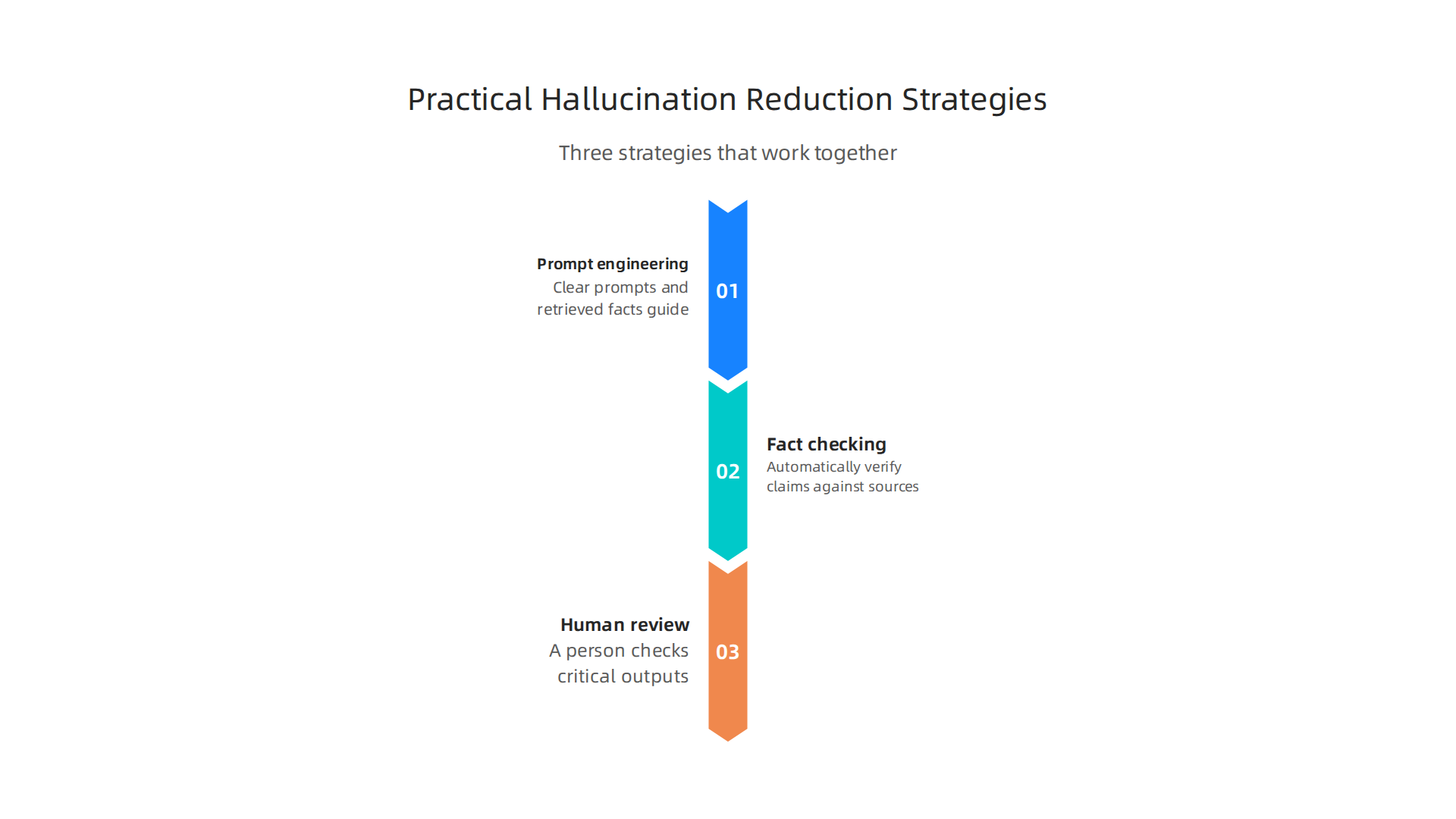
| Strategy | What It Does | Why It Works |
|---|---|---|
| Prompt engineering + RAG | Clear prompts and retrieved facts guide the model | Stops the model from guessing on its own |
| Fact-checking workflows | Automatically verify claims against sources | Catches errors before they reach your audience |
| Human review for high-stakes work | A person checks critical outputs | Adds judgment that AI still lacks |
Start with prompt engineering. Tell the AI exactly what you want and ask it to cite sources. Add retrieval-augmented generation (RAG) so the model pulls facts from your own documents instead of relying on memory. Studies show RAG can reduce hallucinations by 1 to 3 percent, but it does not eliminate them entirely. Pair it with a fact-checking system that cross references claims against trusted data. The AWS blog walks through one way to build a hallucination detection system for RAG based apps.
For important decisions, keep a human in the loop. A person reviewing the AI’s output catches subtle fabrications that automated checks miss. This is essential in fields like healthcare, law, and finance. The Duke library blog reminds us that double checking everything that seems off is still the best defense.
Finally, evaluate your AI regularly against hallucination benchmarks. Use tools from the awesome-hallucination-detection list on GitHub to track progress. Run red teaming exercises where you intentionally try to break the model. This helps you see where your guardrails fail.
Want a step by step guide to set up your own fact checker? Check out our tutorial on how to build an AI fact-checker workflow to catch costly hallucinations.
Prompt Engineering and Retrieval-Augmented Generation (RAG)
The easiest fix starts with your prompts. A clear, specific prompt tells the model exactly what you want.
This works for every system, even models built with strong safety rules like those from Anthropic AI. Vague instructions make the AI guess. And guessing leads to hallucinations.
Write prompts that leave no room for error
Start by removing fuzzy language. Instead of "Explain this topic," try "Summarize the key facts from the provided document. List your sources. Keep it short." Tell the model to think step by step. Set the temperature low, around 0.1 or 0.2, so it sticks to safe answers.
You can also ask the model to cite sources within the response. This makes checking the information much easier. The Kili Technology blog on LLM hallucinations offers more practical tips that still work well in 2026.
Add RAG to ground the AI in real facts
RAG stands for retrieval-augmented generation. Instead of relying on memory, the model pulls facts from your own documents or databases. Think of it as giving the AI a cheat sheet it must use during the test.
A study shared on Newline showed that RAG reduced hallucinations by about 1 to 3 percent. That is not a perfect fix, but it helps a lot. And when you pair it with good prompts, the results get even better.
Combine them for the best results
Prompt engineering and RAG work best together. Write prompts that force the model to use your RAG documents. Ask it to quote directly from those sources. This combination leaves almost no room for made up facts.
To make sure your setup holds up, run red teaming exercises where you try to trick the model. This shows you where your guardrails are weak. And if you want to know what do AI detectors look for, remember they check for quotes, source links, and logical flow all things that strong prompts and RAG help you deliver.
Want a full step by step guide? Check out our tutorial on building an AI fact-checker workflow to catch costly hallucinations.
Automated Fact-Checking and Human-in-the-Loop
Even the best prompts and RAG setups slip up sometimes. That is why you need a second layer of defense. Automated fact-checking tools scan AI outputs and flag potential hallucinations before they cause damage.
So what do AI detectors look for? They check factual consistency, source attribution, and logical flow. When the model makes a claim without backing it up, the tool sends a warning. The AWS blog on detecting hallucinations for RAG-based systems walks through how to build one of these detection systems. And research on fact-checking frameworks shows this approach works best when paired with strong prompting strategies.
But machines miss subtle mistakes. They do not understand context the way a person does. That is where human reviewers come in. A human brings domain expertise and real world judgment. During a red teaming exercise, you see exactly where both the model and the automated checks fail.
This matters even more for physical AI systems. A robot or a self driving car cannot afford a hallucination. An error means real harm. Automated checks plus human review keep those risks low.
Think about honeypot cyber security. It tricks attackers into revealing themselves. An automated fact-checker does the same to a hallucinating model. It traps the error before it spreads.
Models like those from anthropic ai already have strong safety features. But even they benefit from this two layer approach. Just do not let the review process slow you down. Design it so automation handles the first pass. Only send flagged items to humans.
To see how human insight catches what machines miss, read our guide on how AI data labeling jobs reduce AI hallucinations.
Building an Organizational Culture of AI Verification
Automated fact-checking and human review only work if your team actually uses them. The real challenge is changing how people think about AI outputs. You can have the best detection tools available, but if nobody questions what the model says, hallucinations slip through anyway.
That is why building an organizational culture of AI verification matters as much as any technology. Trust in AI does not come from a single fix.

It comes from continuous education and a shared habit of checking results.
Start with clear policies. Every person who touches AI output needs to know what do AI detectors look for. They look for missing sources, contradictory facts, and claims that sound too perfect. Your team should understand these flags without thinking twice.
Training makes this real. Run regular workshops where people practice detecting hallucinations. A red teaming exercise is a great way to do this. Have one group try to break the model while another catches the errors. This hands-on practice builds instincts that no manual can teach.
You also need tools that fit into daily work. The AWS blog on detecting hallucinations for RAG-based systems shows how to build automated checks that do not slow people down. But tools alone are not enough. You need a culture where reporting a hallucination feels safe and helpful, not embarrassing.
Think about it like honeypot cyber security. Cybersecurity teams set up traps to learn how attackers operate. In the same way, every reported hallucination teaches your organization where the model struggles. Encourage your team to flag mistakes openly. Treat each report as a learning opportunity, not a failure.
This matters even more for physical AI systems. A self-driving car or a warehouse robot cannot wait for a policy review. The verification culture must be automatic. Every engineer, operator, and safety officer needs to double-check outputs as a reflex.
Even advanced models like those from anthropic ai benefit from this approach. They are not perfect. A strong culture catches the gaps that technology misses.
For a practical step-by-step guide on setting up your verification workflow, read our article on how to build an AI fact checker workflow.
Make verification a habit, not an afterthought. That is how you build lasting trust in AI.
Summary
This article explains why AI hallucinations—confident but false outputs from large language models—remain a major business and safety problem in 2026, with error rates across top models often between 22% and 50% and heavy verification costs per employee. It walks through what hallucinations are, the two main types (intrinsic and extrinsic), and the technical causes rooted in training data, model design, and sampling settings like temperature. The piece covers practical mitigations you can apply today: prompt engineering, retrieval-augmented generation (RAG), calibration of sampling strategies, automated fact‑checking, red teaming, and keeping humans in the loop for high‑stakes work. It also profiles Anthropic’s Constitutional AI approach, which embeds rules during training so models learn to avoid fabrications or say